

Meta presenta il più grande, il più intelligente, il più libero da royalty Llama 3.1 405B AI

Meta ha presentato il suo Llama 3.1 405B AI per l'uso gratuito. Il modello linguistico di grandi dimensioni (LLM) da 750 GB e 405 miliardi di parametri è uno dei più grandi mai rilasciati, consentendogli di competere, con la sua finestra di input ampliata a 128K token, con i fiori all'occhiello dell'AI come Anthropic Claude 3.5 Sonnet e OpenAI GPT-4o. A differenza dei concorrenti a pagamento e closed-source, i lettori possono personalizzare ed eseguire l'LLM gratuito sui propri computer dotati di schede grafiche (GPU) Nvidia estremamente potenti.
Creazione ed energia
Meta ha sfruttato fino a 16.384 GPU 700W TDP GPU H100 sulla sua piattaforma server Meta Grand Teton AI per produrre i 3,8 x 10^25 FLOP necessari per creare un modello di 405 miliardi di parametri su 16,55 trilioni di token (1000 token sono circa 750 parole). I guasti legati alle GPU hanno causato il 57,3% dei tempi di inattività durante il pre-training, con il 30,1% dovuto a GPU difettose.
Sono stati trascorsi oltre 54 giorni di pre-addestramento dell'IA sui documenti, con un totale di 39,3 milioni di ore di GPU utilizzate per addestrare Llama 3.1 405B. Secondo una rapida stima, il consumo di elettricità durante l'addestramento è stato di oltre 11 GWh, con 11.390 tonnellate di gas serra equivalenti a CO2 rilasciate.
Sicurezza e prestazioni
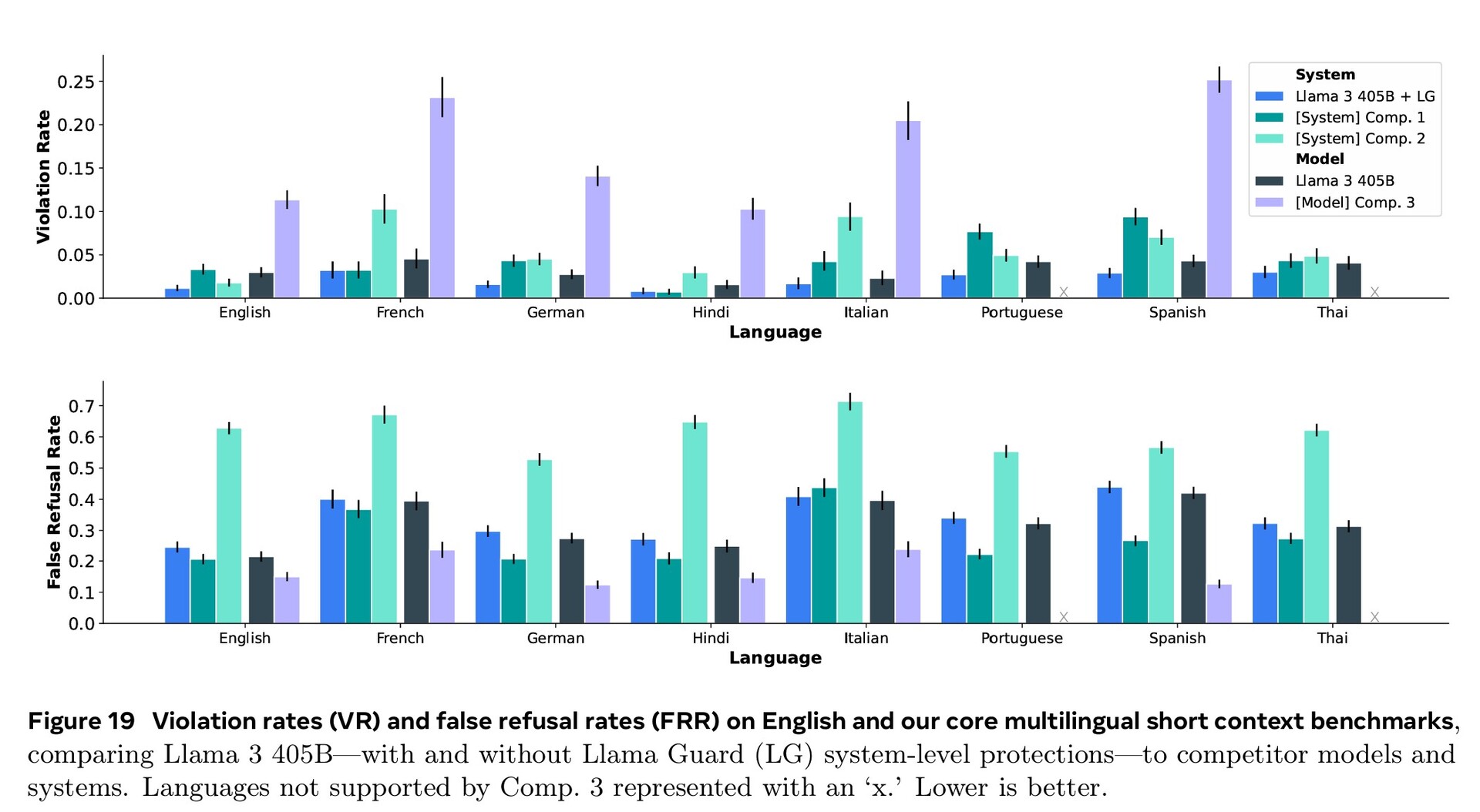
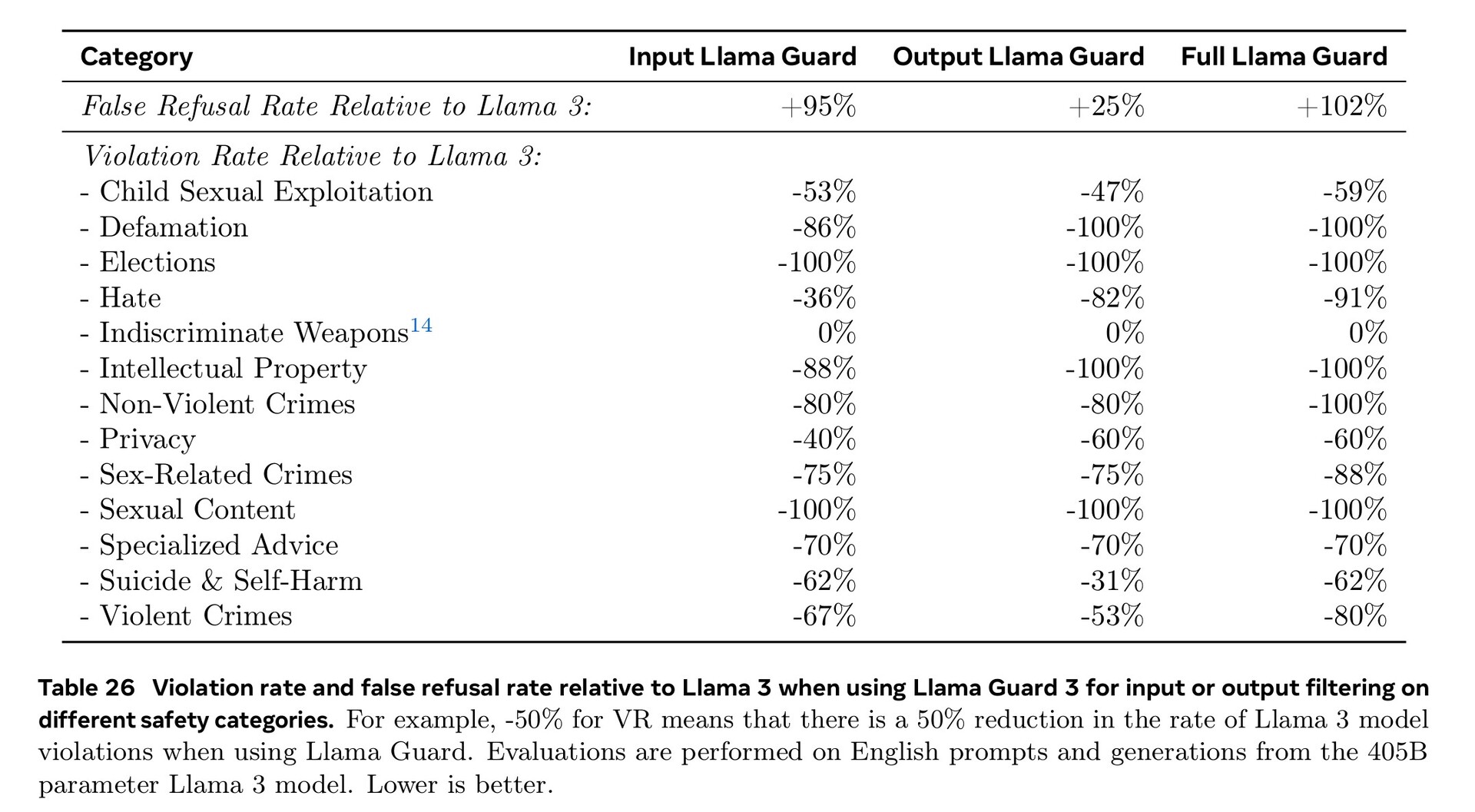
L'addestramento estensivo nei settori della cybersicurezza, della sicurezza dei bambini, degli attacchi chimici e biologici, dell'iniezione immediata e altro ancora, unitamente al filtraggio del testo in ingresso e in uscita utilizzando Llama Guard 3, ha portato a prestazioni di sicurezza migliori rispetto ai modelli AI concorrenti. Tuttavia, la minore quantità di documenti in lingua straniera disponibili per l'addestramento fa sì che Llama 3.1 sia più propenso a rispondere a domande pericolose in portoghese o francese che in inglese.
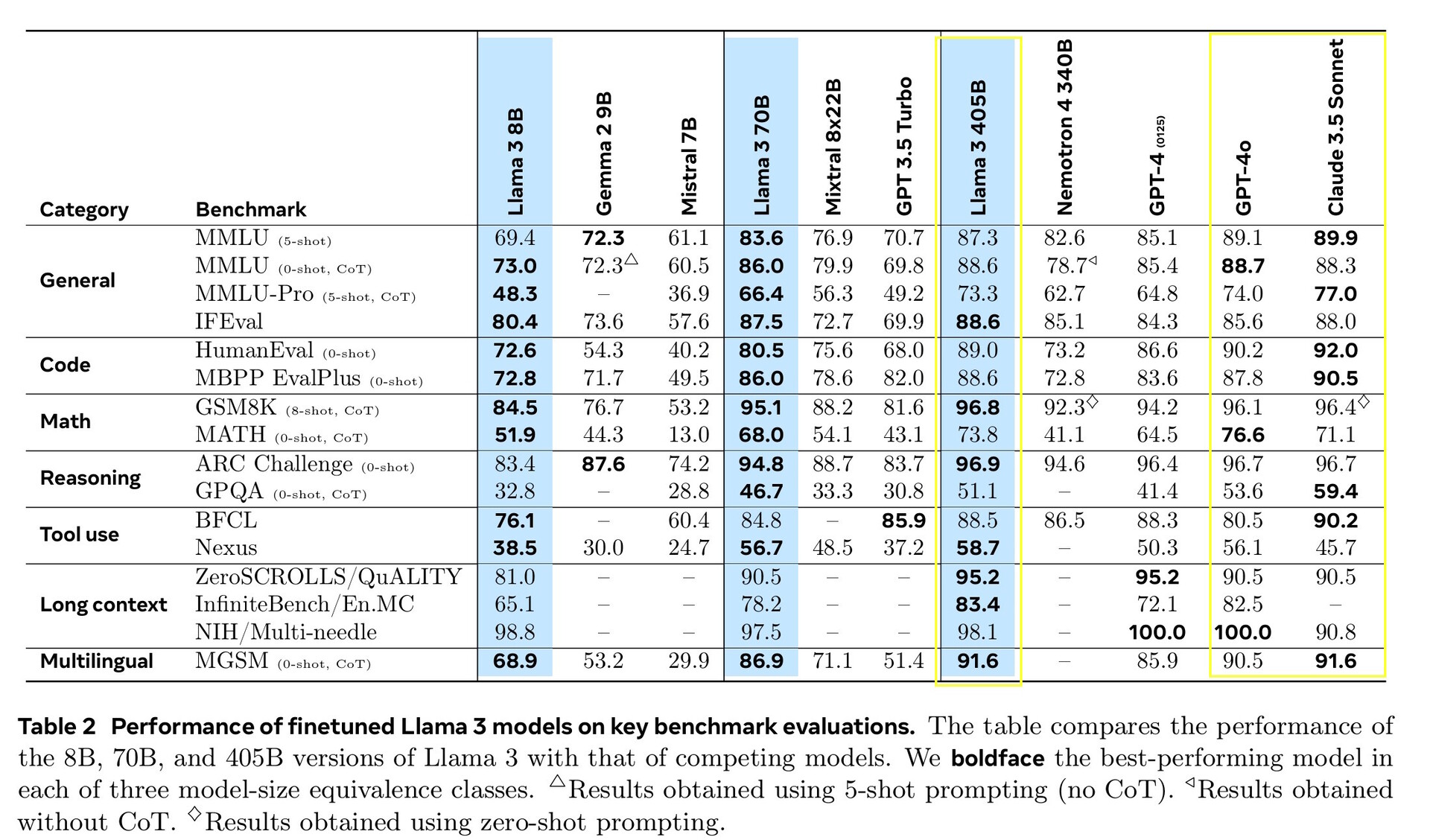
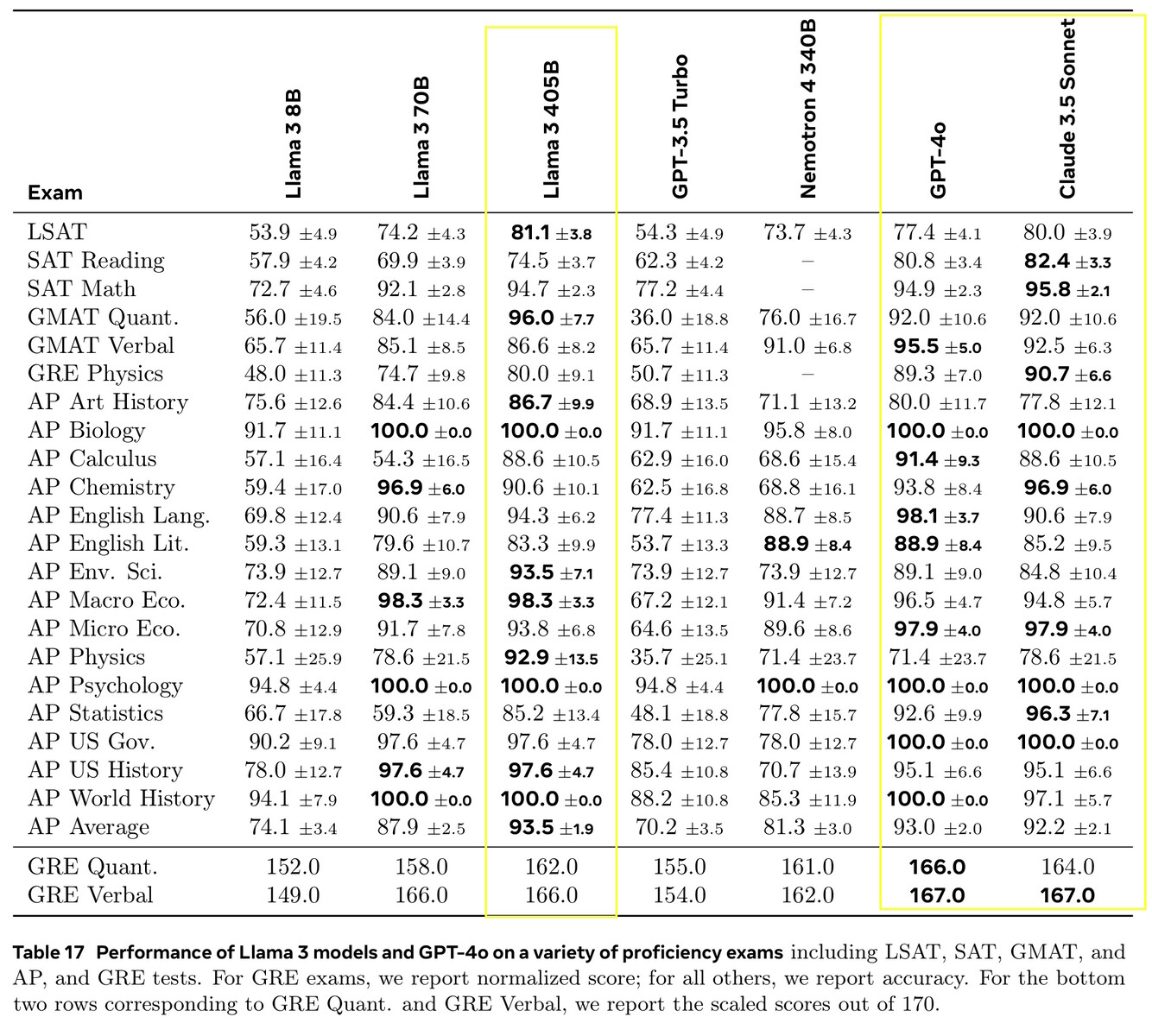
Llama 3.1 405B ha ottenuto punteggi compresi tra il 51,1 e il 96,6% nei test di AI di livello universitario e universitario, in linea con Claude 3.5 Sonnet e GPT-4o. Nei test di vita reale valutati dagli esseri umani, GPT-4o ha fornito risposte migliori il 52,9% più spesso di Llama. Il modello non sa nulla al di là della data limite di conoscenza del dicembre 2023, ma può raccogliere le ultime informazioni online utilizzando Brave Searchrisolvere problemi matematici utilizzando Wolfram Alphae risolvere problemi di codifica con l'interprete Python di https://www.python.org/.
Requisiti
I ricercatori interessati ad eseguire Llama 3.1 405B localmente avranno bisogno di computer estremamente potenti con 750 GB di spazio di archiviazione libero. L'esecuzione del modello completo richiede otto GPU Nvidia A100 o simili, che forniscono due nodi di MP16 e 810 GB di GPU VRAM per l'inferenza, in un sistema con 1 TB di RAM. Meta ha rilasciato versioni più piccole che richiedono meno risorse, ma con prestazioni peggiori: Llama 3.1 8B e 70B. Llama 3.1 8B ha bisogno solo di 16 GB di GPU VRAM, quindi funzionerà bene su un sistema ben equipaggiato di Nvidia 4090(come questo computer portatile su Amazon), più o meno al livello di GPT-3.5 Turbo. I lettori che desiderano semplicemente utilizzare un'intelligenza artificiale superiore possono installare un'applicazione come Anthropic Android o applicazione iOS.
Fonte(i)
Modello linguistico grande
Vi presentiamo Llama 3.1: I nostri modelli più capaci fino ad oggi
23 luglio 2024
lettura di 15 minuti
Da notare che Meta si impegna a rendere l'intelligenza artificiale accessibile a tutti:
Meta si impegna a rendere l'IA apertamente accessibile. Legga la lettera di Mark Zuckerberg che spiega perché l'open source è un bene per gli sviluppatori, per Meta e per il mondo.
Per portare l'intelligenza aperta a tutti, i nostri ultimi modelli ampliano la lunghezza del contesto a 128K, aggiungono il supporto di otto lingue e includono Llama 3.1 405B, il primo modello di AI open source di frontiera.
Llama 3.1 405B è una classe a sé stante, con una flessibilità, un controllo e delle capacità all'avanguardia senza pari che rivaleggiano con i migliori modelli closed source. Il nostro nuovo modello consentirà alla comunità di sbloccare nuovi flussi di lavoro, come la generazione di dati sintetici e la distillazione dei modelli.
Stiamo continuando a costruire Llama come un sistema, fornendo altri componenti che funzionano con il modello, compreso un sistema di riferimento. Vogliamo fornire agli sviluppatori gli strumenti per creare agenti personalizzati e nuovi tipi di comportamenti agonici. Stiamo rafforzando questo aspetto con nuovi strumenti di sicurezza e protezione, tra cui Llama Guard 3 e Prompt Guard, per aiutare a costruire in modo responsabile. Stiamo anche rilasciando una richiesta di commenti sull'API Llama Stack, un'interfaccia standard che speriamo renda più facile per i progetti di terze parti sfruttare i modelli Llama.
L'ecosistema è pronto a partire con oltre 25 partner, tra cui AWS, NVIDIA, Databricks, Groq, Dell, Azure, Google Cloud e Snowflake che offrono servizi fin dal primo giorno.
Provi Llama 3.1 405B negli Stati Uniti su WhatsApp e su meta.ai ponendo una domanda impegnativa di matematica o di codifica.
LETTURE CONSIGLIATE
Espandere l'ecosistema Llama in modo responsabile
L'ecosistema dei lama: Passato, presente e futuro
Fino ad oggi, i modelli linguistici open source di grandi dimensioni sono rimasti per lo più indietro rispetto alle loro controparti chiuse, in termini di capacità e prestazioni. Ora, stiamo inaugurando una nuova era con l'open source alla guida. Stiamo rilasciando pubblicamente Meta Llama 3.1 405B, che riteniamo sia il modello di base open source più grande e più capace al mondo. Con oltre 300 milioni di download totali di tutte le versioni di Llama, siamo solo all'inizio.
Presentazione di Llama 3.1
Llama 3.1 405B è il primo modello disponibile che rivaleggia con i migliori modelli AI per quanto riguarda le capacità all'avanguardia in termini di conoscenza generale, governabilità, matematica, uso di strumenti e traduzione multilingue. Con il rilascio del modello 405B, siamo pronti a potenziare l'innovazione, con opportunità di crescita e di esplorazione senza precedenti. Riteniamo che l'ultima generazione di Llama darà il via a nuove applicazioni e paradigmi di modellazione, tra cui la generazione di dati sintetici per consentire il miglioramento e l'addestramento di modelli più piccoli, nonché la distillazione dei modelli, una capacità che non è mai stata raggiunta su questa scala nell'open source.
Nell'ambito di quest'ultima release, stiamo introducendo versioni aggiornate dei modelli 8B e 70B. Questi sono multilingue e hanno una lunghezza del contesto significativamente maggiore di 128K, un utilizzo di strumenti all'avanguardia e capacità di ragionamento complessivamente più forti. Ciò consente ai nostri ultimi modelli di supportare casi d'uso avanzati, come la riassunzione di testi lunghi, gli agenti di conversazione multilingue e gli assistenti di codifica. Abbiamo anche apportato modifiche alla nostra licenza, consentendo agli sviluppatori di utilizzare i risultati dei modelli Llama, compreso il 405B, per migliorare altri modelli. Fedeli al nostro impegno verso l'open source, a partire da oggi, mettiamo questi modelli a disposizione della comunità per il download su llama.meta.com e Hugging Face e disponibili per lo sviluppo immediato sul nostro ampio ecosistema di piattaforme partner.
Valutazioni dei modelli
Per questa release, abbiamo valutato le prestazioni su oltre 150 set di dati di riferimento che coprono un'ampia gamma di lingue. Inoltre, abbiamo eseguito valutazioni umane approfondite che confrontano Llama 3.1 con modelli concorrenti in scenari reali. La nostra valutazione sperimentale suggerisce che il nostro modello di punta è competitivo con i principali modelli di fondazione in una serie di compiti, tra cui GPT-4, GPT-4o e Claude 3.5 Sonnet. Inoltre, i nostri modelli più piccoli sono competitivi con i modelli chiusi e aperti che hanno un numero simile di parametri.
Architettura del modello
Essendo il nostro modello più grande, l'addestramento di Llama 3.1 405B su oltre 15 mila miliardi di token ha rappresentato una sfida importante. Per consentire l'addestramento su questa scala e ottenere i risultati che abbiamo ottenuto in un tempo ragionevole, abbiamo ottimizzato in modo significativo il nostro stack di addestramento completo e abbiamo spinto l'addestramento del modello su oltre 16 mila GPU H100, rendendo il 405B il primo modello Llama addestrato su questa scala.
Per affrontare questo problema, abbiamo fatto delle scelte di progettazione che si concentrano sul mantenimento del processo di sviluppo del modello scalabile e semplice.
Abbiamo optato per un'architettura di modello trasformatore standard di solo decodificatore con piccoli adattamenti, piuttosto che un modello misto di esperti, per massimizzare la stabilità dell'addestramento.
Abbiamo adottato una procedura di post-formazione iterativa, in cui ogni round utilizza la messa a punto supervisionata e l'ottimizzazione diretta delle preferenze. Questo ci ha permesso di creare dati sintetici della massima qualità per ogni round e di migliorare le prestazioni di ogni capacità.
Rispetto alle versioni precedenti di Llama, abbiamo migliorato sia la quantità che la qualità dei dati utilizzati per il pre- e il post-training. Questi miglioramenti includono lo sviluppo di pipeline di pre-elaborazione e curation più attente per i dati di pre-formazione, lo sviluppo di approcci di garanzia della qualità e di filtraggio più rigorosi per i dati di post-formazione.
Come previsto dalle leggi di scala per i modelli linguistici, il nostro nuovo modello di punta supera i modelli più piccoli addestrati con la stessa procedura. Abbiamo anche utilizzato il modello di parametri 405B per migliorare la qualità post-training dei nostri modelli più piccoli.
Per supportare l'inferenza di produzione su larga scala per un modello della scala del 405B, abbiamo quantizzato i nostri modelli da 16 bit (BF16) a 8 bit (FP8) numerici, riducendo in modo efficace i requisiti di calcolo necessari e consentendo al modello di funzionare in un singolo nodo del server.
Messa a punto di istruzioni e chat
Con Llama 3.1 405B, abbiamo cercato di migliorare l'utilità, la qualità e la capacità di seguire le istruzioni dettagliate del modello in risposta alle istruzioni dell'utente, garantendo al contempo alti livelli di sicurezza. Le nostre maggiori sfide sono state il supporto di più funzionalità, la finestra di contesto da 128K e l'aumento delle dimensioni del modello.
Nel post-training, produciamo i modelli di chat finali eseguendo diversi cicli di allineamento sul modello pre-addestrato. Ogni ciclo comprende la messa a punto supervisionata (SFT), il campionamento di scarto (RS) e l'ottimizzazione diretta delle preferenze (DPO). Utilizziamo la generazione di dati sintetici per produrre la maggior parte dei nostri esempi di SFT, iterando più volte per produrre dati sintetici di qualità sempre più elevata in tutte le capacità. Inoltre, investiamo in molteplici tecniche di elaborazione dei dati per filtrare questi dati sintetici alla massima qualità. Questo ci permette di scalare la quantità di dati di messa a punto tra le varie capacità.
Bilanciamo attentamente i dati per produrre un modello di alta qualità in tutte le capacità. Ad esempio, manteniamo la qualità del nostro modello sui benchmark a contesto breve, anche quando si estende a un contesto di 128K. Allo stesso modo, il nostro modello continua a fornire risposte di massima utilità, anche quando aggiungiamo mitigazioni di sicurezza.
Il sistema Llama
I modelli Llama sono sempre stati concepiti per funzionare come parte di un sistema complessivo che può orchestrare diversi componenti, compresa la chiamata di strumenti esterni. La nostra visione è quella di andare oltre i modelli di base per dare agli sviluppatori l'accesso a un sistema più ampio che dia loro la flessibilità di progettare e creare offerte personalizzate in linea con la loro visione. Questo pensiero è iniziato l'anno scorso, quando abbiamo introdotto per la prima volta l'incorporazione di componenti al di fuori del nucleo di LLM.
Nell'ambito del nostro impegno costante per sviluppare l'AI in modo responsabile al di là del livello del modello e per aiutare gli altri a fare lo stesso, stiamo rilasciando un sistema di riferimento completo che comprende diverse applicazioni campione e include nuovi componenti come Llama Guard 3, un modello di sicurezza multilingue e Prompt Guard, un filtro di iniezione di messaggi. Queste applicazioni campione sono open source e possono essere sviluppate dalla comunità.
L'implementazione dei componenti in questa visione del Sistema Llama è ancora frammentata. Ecco perché abbiamo iniziato a collaborare con l'industria, le startup e la comunità in generale, per contribuire a definire meglio le interfacce di questi componenti. A tal fine, stiamo pubblicando una richiesta di commenti su GitHub per quello che chiamiamo "Llama Stack" Llama Stack è un insieme di interfacce standardizzate e opinionate per la costruzione di componenti canonici della catena di strumenti (messa a punto, generazione di dati sintetici) e di applicazioni agenziali. La nostra speranza è che queste vengano adottate in tutto l'ecosistema, il che dovrebbe facilitare l'interoperabilità.
Accogliamo con favore il feedback e i modi per migliorare la proposta. Siamo entusiasti di far crescere l'ecosistema intorno a Llama e di ridurre le barriere per gli sviluppatori e i fornitori di piattaforme.
L'apertura favorisce l'innovazione
A differenza dei modelli chiusi, i pesi dei modelli Llama sono disponibili per il download. Gli sviluppatori possono personalizzare completamente i modelli per le loro esigenze e applicazioni, allenarsi su nuovi set di dati e condurre ulteriori messe a punto. Ciò consente alla comunità di sviluppatori più ampia e al mondo di sfruttare al meglio la potenza dell'AI generativa. Gli sviluppatori possono personalizzare completamente le loro applicazioni ed eseguirle in qualsiasi ambiente, anche on premise, nel cloud o persino localmente su un laptop, il tutto senza condividere i dati con Meta.
Sebbene molti possano sostenere che i modelli chiusi siano più convenienti, i modelli Llama offrono un costo per token tra i più bassi del settore, secondo i test di Artificial Analysis. E come ha notato Mark Zuckerberg, l'open source garantirà che più persone in tutto il mondo abbiano accesso ai benefici e alle opportunità dell'IA, che il potere non sia concentrato nelle mani di pochi e che la tecnologia possa essere impiegata in modo più uniforme e sicuro in tutta la società. Ecco perché continuiamo a fare passi avanti nel percorso che porterà l'AI ad accesso aperto a diventare lo standard del settore.
Abbiamo visto la comunità costruire cose straordinarie con i modelli Llama del passato, tra cui un compagno di studi AI costruito con Llama e distribuito in WhatsApp e Messenger, un LLM su misura per il settore medico, progettato per aiutare a guidare il processo decisionale clinico, e una startup sanitaria no-profit in Brasile che rende più facile per il sistema sanitario organizzare e comunicare le informazioni dei pazienti sul loro ricovero, il tutto in un modo sicuro per i dati. Non vediamo l'ora di vedere cosa costruiranno con i nostri ultimi modelli grazie al potere dell'open source.
Costruire con Llama 3.1 405B
Per lo sviluppatore medio, utilizzare un modello in scala come il 405B è una sfida. Pur essendo un modello incredibilmente potente, riconosciamo che richiede risorse di calcolo e competenze significative per lavorare. Abbiamo parlato con la comunità e ci siamo resi conto che lo sviluppo dell'intelligenza artificiale generativa non si limita ai modelli di richiesta. Vogliamo consentire a tutti di ottenere il massimo dal 405B, tra cui:
Inferenza in tempo reale e in batch
Messa a punto supervisionata
Valutazione del modello per l'applicazione specifica
Pre-training continuo
Generazione Aumentata dal Recupero (RAG)
Richiamo di funzioni
Generazione di dati sintetici
È qui che l'ecosistema Llama può aiutarla. Il primo giorno, gli sviluppatori possono sfruttare tutte le funzionalità avanzate del modello 405B e iniziare a costruire immediatamente. Gli sviluppatori possono anche esplorare flussi di lavoro avanzati come la generazione di dati sintetici di facile utilizzo, seguire le indicazioni chiavi in mano per la distillazione del modello e abilitare la RAG senza soluzione di continuità con le soluzioni dei partner, tra cui AWS, NVIDIA e Databricks. Inoltre, Groq ha ottimizzato l'inferenza a bassa latenza per le implementazioni nel cloud, mentre Dell ha ottenuto ottimizzazioni simili per i sistemi on-premise.
Abbiamo collaborato con i progetti chiave della comunità, come vLLM, TensorRT e PyTorch, per creare un supporto fin dal primo giorno, per garantire che la comunità sia pronta per la distribuzione in produzione.
Ci auguriamo che il nostro rilascio del 405B stimoli anche l'innovazione nella comunità più ampia, per rendere più facile l'inferenza e la messa a punto di modelli di questa portata e consentire la prossima ondata di ricerca nella distillazione dei modelli.
Provi oggi la collezione di modelli di Llama 3.1
Non vediamo l'ora di vedere cosa farà la comunità con questo lavoro. C'è un grande potenziale per costruire nuove esperienze utili utilizzando il multilinguismo e la maggiore lunghezza del contesto. Con Llama Stack e i nuovi strumenti di sicurezza, non vediamo l'ora di continuare a costruire insieme alla comunità open source in modo responsabile. Prima di rilasciare un modello, lavoriamo per identificare, valutare e mitigare i rischi potenziali attraverso diverse misure, tra cui gli esercizi di scoperta dei rischi prima della distribuzione, il red teaming e la messa a punto della sicurezza. Ad esempio, conduciamo un'ampia attività di red teaming con esperti esterni e interni per sottoporre i modelli a stress test e trovare modi inaspettati in cui potrebbero essere utilizzati. (Per saperne di più su come stiamo scalando la nostra collezione di modelli Llama 3.1 in modo responsabile, legga questo post sul blog)
Anche se questo è il nostro modello più grande, crediamo che ci sia ancora molto terreno da esplorare in futuro, tra cui dimensioni più adatte ai dispositivi, modalità aggiuntive e maggiori investimenti nel livello della piattaforma agente.
Questo lavoro è stato supportato dai nostri partner della comunità AI. Vorremmo ringraziare e riconoscere (in ordine alfabetico): Accenture, Amazon Web Services, AMD, Anyscale, CloudFlare, Databricks, Dell, Deloitte, Fireworks.ai, Google Cloud, Groq, Hugging Face, IBM WatsonX, Infosys, Intel, Kaggle, Microsoft Azure, NVIDIA, OctoAI, Oracle Cloud, PwC, Replicate, Sarvam AI, Scale.AI, SNCF, Snowflake, Together AI e il progetto vLLM sviluppato nello Sky Computing Lab della UC Berkeley.

