

Le comunicazioni interne trapelate rivelano che Nvidia raccoglie ogni giorno una vita di video di YouTube per addestrare il modello di AI video, e Jensen è soddisfatta dei progressi

Nvidia sta addestrando il suo Omniverse, le auto a guida autonoma e le auto "umane digitali" sulla base dei dati raccolti da "80 anni di video al giorno" da YouTube e altre fonti, come ha rivelato un'indagine di 404 Media.
Le comunicazioni interne trapelate, ottenute da 404 Media, indicano che Nvidia sta usando questi dati per addestrare il suo modello di mondo video AI denominato Cosmos (da non confondere con il servizio di apprendimento profondo esistente dell'azienda Cosmos). Cosmos è internamente destinato ad essere un modello che alimenterà altre linee di Nvidia, tra cui GeForce, l'architettura GPU, DGX, i framework di Deep Learning, Omniverse, Avatar, Project GR00T e i veicoli autonomi.
I dirigenti di Nvidia hanno definito Cosmos come un modello di base all'avanguardia"che incapsula la simulazione del trasporto della luce, la fisica e l'intelligenza in un unico luogo per sbloccare varie applicazioni a valle fondamentali per Nvidia"
404 Media ha avuto accesso ai messaggi Slack dei dipendenti interni che hanno rivelato come il personale abbia utilizzato il programma a riga di comando yt-dlp per scaricare i video di YouTube utilizzando da 20 a 30 macchine virtuali AWS che aggiornano gli indirizzi IP per evitare di essere bloccati da YouTube. Il sito di condivisione video è stato la fonte principale per lo scraping dei video, con i dipendenti che hanno preso in considerazione anche altre fonti come Netflix e Discovery Channel.
Le comunicazioni su Slack mostrano i dipendenti che discutono delle ramificazioni legali dello scraping di contenuti protetti da copyright per addestrare l'AI, per poi essere liquidati dai responsabili del progetto come una decisione esecutiva, di cui non devono preoccuparsi.
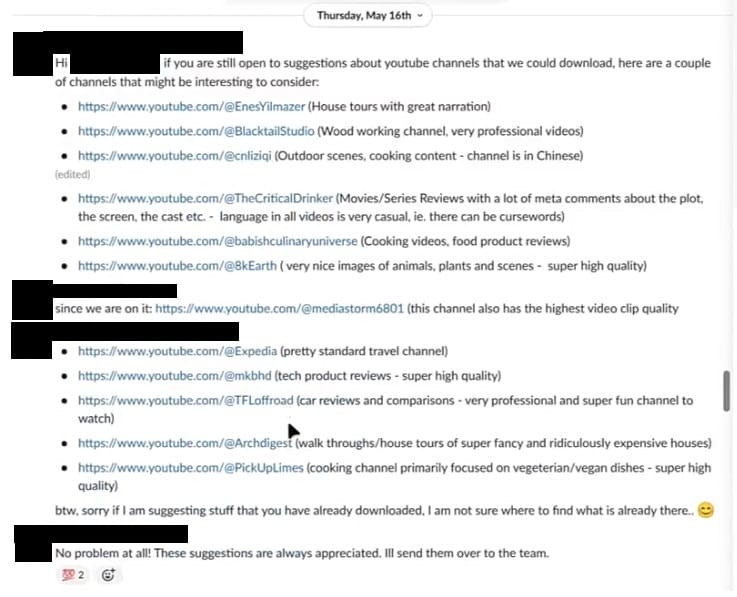
I canali YouTube popolari che i dipendenti di Nvidia hanno inserito nella lista includono MKBHD, PickUpLimes, Architectural Digest, Expedia, Mediastorm6801, 8kEarth e The CriticalDrinker, tra gli altri.
Contattati da 404 Media, sia YouTube che Netflix hanno dichiarato che lo scraping di contenuti sulle loro piattaforme per addestrare modelli di intelligenza artificiale è una chiara violazione dei loro termini di servizio.
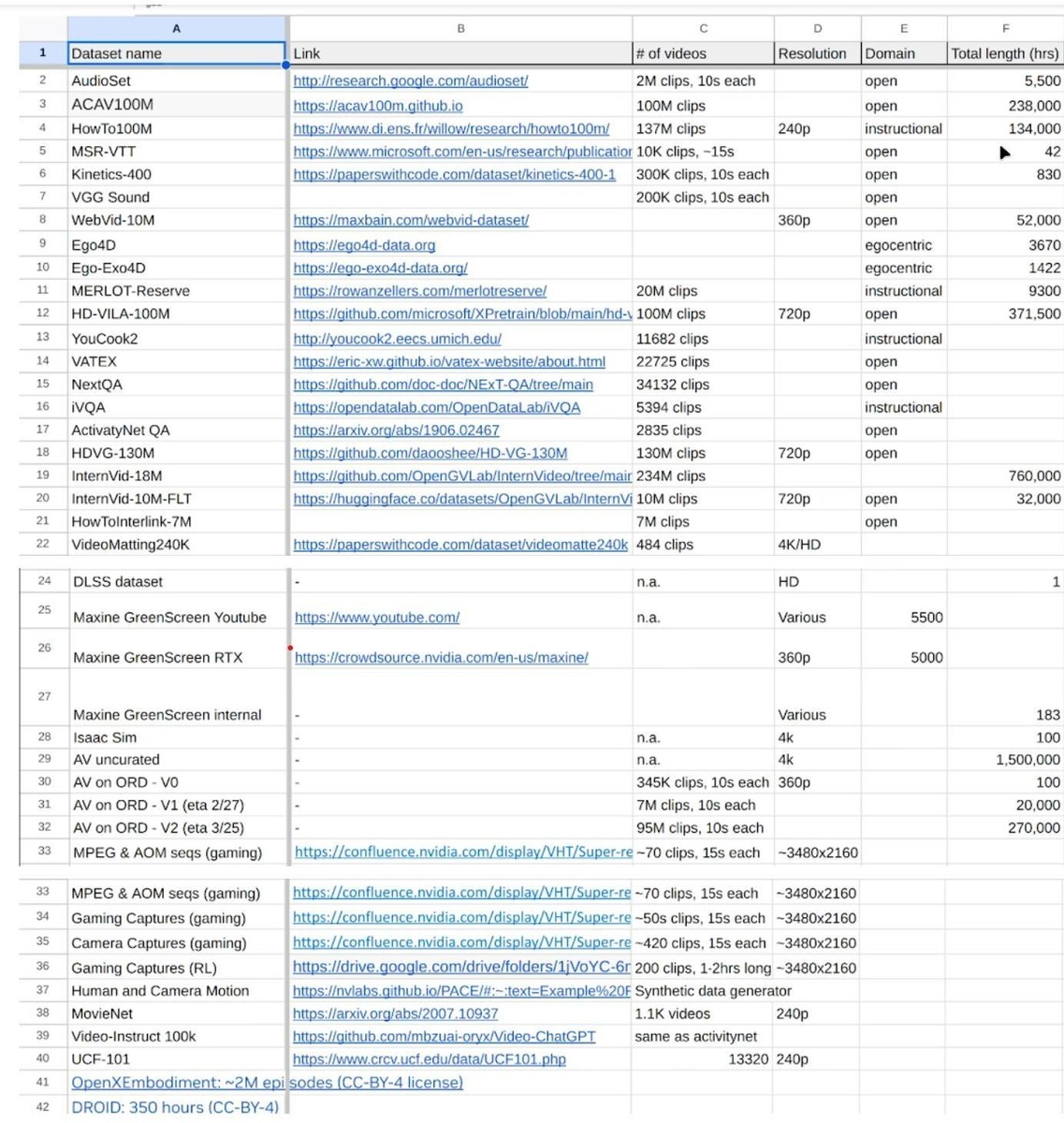
L'uso di dati protetti da copyright per addestrare modelli di AI è ancora una zona grigia dal punto di vista legale. I dataset pubblici come InternVid-10MHD-VG-130Me altri basati su milioni di video di YouTube, ma sono destinati solo alla ricerca accademica e non a scopi commerciali. Anche se Nvidia dispone di ricercatori accademici, i risultati finiranno per diventare prodotti commerciali.
Ci sono state poche legislazioni che prevedono standard di trasparenza e l'obbligo per le aziende che lavorano su modelli di AI fondamentali di collaborare con l'FTC e l'Ufficio del Copyright. Ma le aziende non divulgano necessariamente i loro set di dati di origine, il che rende molto più difficile la verifica.
Poiché le principali aziende di AI continuano a mettere le mani su tutti i dati pubblici disponibili per addestrare modelli più efficaci, le modifiche legislative sono una necessità impellente per garantire la sicurezza dei consumatori e proteggere la proprietà intellettuale dei creatori.
L'anno scorso, il New York Times ha citato in giudizio OpenAI e Microsoft per l'uso non autorizzato degli articoli protetti da copyright della pubblicazione per addestrare i modelli di AI. A maggio, gli artisti visivi hanno intentato una causa contro Stability AI, Midjourney, DeviantArt e Runway AI per aver utilizzato copie del loro lavoro per addestrare modelli AI senza autorizzazione.
YouTube si sta rivelando una miniera di dati per le aziende di AI. Recentemente, Wired ha riferito che i pesi massimi, tra cui Apple, Nvidia, Anthropic e Salesforce, hanno raschiato i sottotitoli di 173.536 video di YouTube da oltre 48.000 canali per addestrare le loro AI.
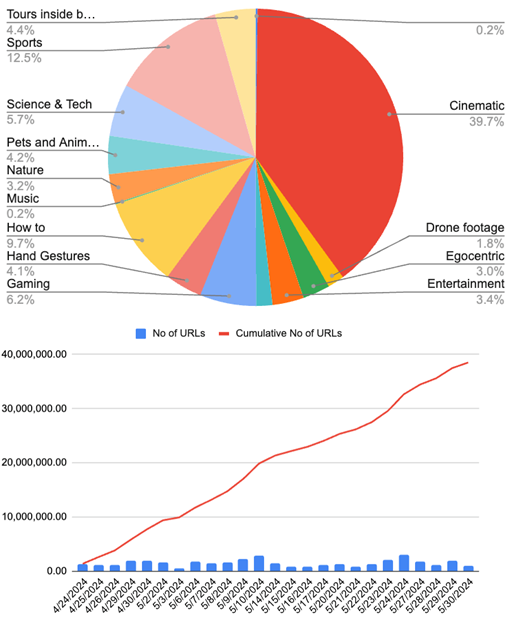
Fino alla fine di maggio, il personale di Nvidia ha annunciato internamente di aver raccolto 38,5 milioni di URL di video, la maggior parte dei quali erano contenuti cinematografici. Gli ingegneri hanno anche aggiunto set di dati come Ego-Exo4DEgo4D, HOI4De i dati di gioco di GeForce Now.
Mentre Ego-Exo4D ed Ego4D possono essere concessi in licenza per uso accademico e commerciale, HOI4D è distribuito con una licenza CC BY-NC che vieta espressamente l'uso commerciale.
Il team sta attualmente addestrando un modello 1B con 16 nodi ciascuno, con l'intenzione di scalare fino a 10B.
Nvidia ha dichiarato a 404 Media via e-mail:"I nostri modelli e i nostri sforzi di ricerca sono in piena conformità con la lettera e lo spirito della legge sul copyright"
Nel frattempo, il CEO di Nvidia Jensen Huang sembra essere soddisfatto dei progressi che il suo staff sta facendo.
Secondo quanto riferito, ha esclamato: "Ottimo aggiornamento. Molte aziende devono costruire video FM [modelli fondazionali]. Noi possiamo offrire una pipeline completamente accelerata"
SCOOP from @samleecole: Leaked Slacks and documents show the incredible scale of NVidia's AI scraping: 80 years — "a human lifetime" of videos every day. Had approval from highest levels of company despite staff legal/ethical concerns:https://t.co/DydXOyffUQ
— Jason Koebler (@jason_koebler) August 5, 2024
Fonte(i)
404 Media (richiede l'iscrizione)











