

La tecnologia AI dell'Università di Washington consente a chi indossa le cuffie di scegliere suoni specifici da ascoltare

Un team guidato da ricercatori informatici dell'Università di Washington (UofW) ha creato il software AI per cuffie che consentono a chi le indossa di selezionare suoni specifici da ascoltare. A differenza delle cuffie a cancellazione di rumore che filtrano semplicemente tutto tranne le voci, la nuova rete neurale consente agli utenti di selezionare suoni specifici, come il cinguettio di un uccello.
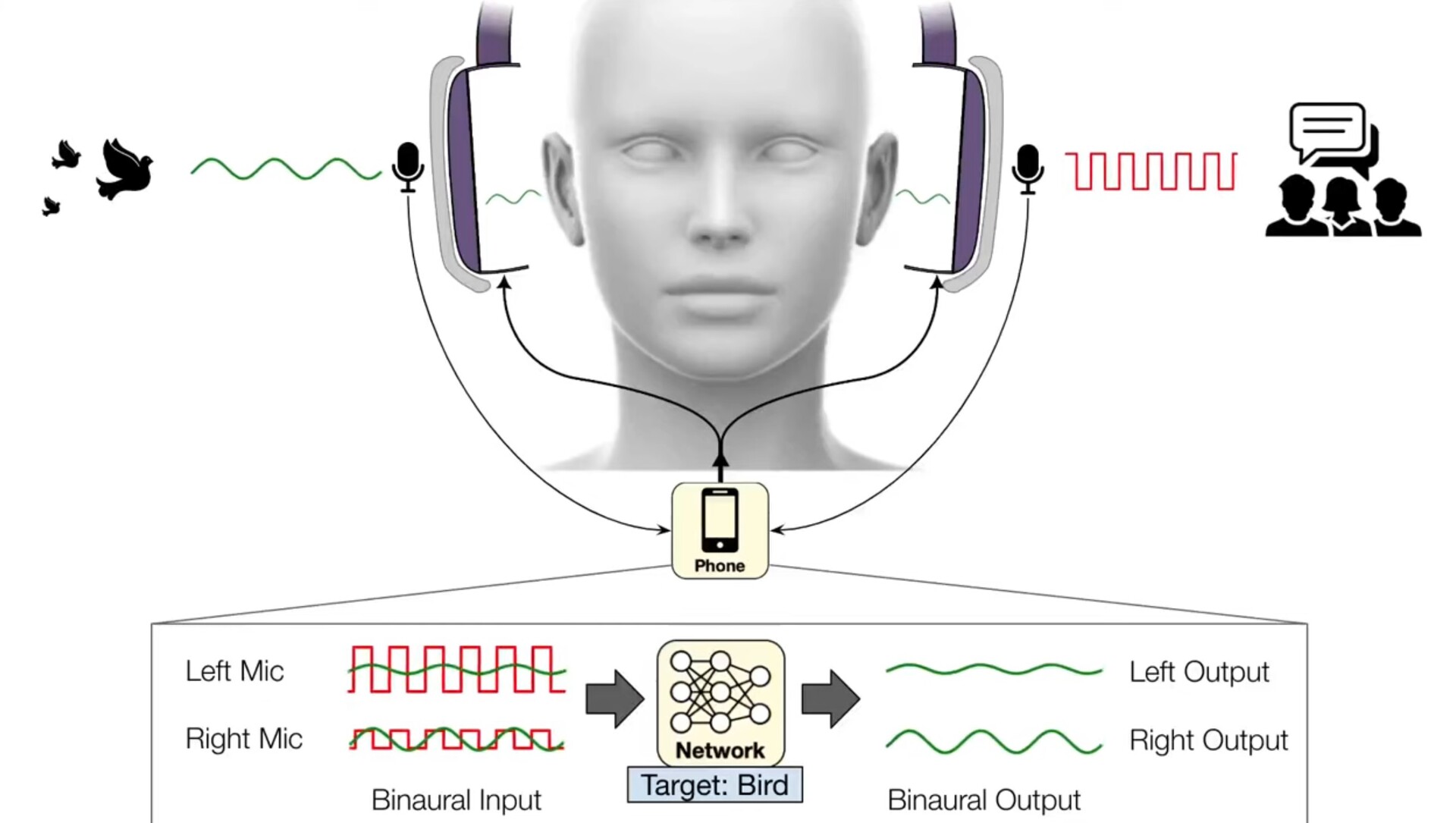
Le cuffie precedenti, come gli auricolari INZONE di Sony(disponibili su Amazon) utilizzano DSEE Extreme, Speak-to-Chate AI DNNaI per migliorare la qualità della musica e del parlato, lasciando automaticamente passare le voci attraverso la cancellazione del rumore quando iniziano le conversazioni. Il lavoro dell'UofW fa un passo avanti consentendo agli ascoltatori di scegliere tra 20 tipi diversi di suoni da ascoltare, come il cinguettio degli uccelli, l'oceano, il bussare alla porta e lo sciacquone del bagno, filtrando tutto il resto. Chiamato udito semantico, questo permette agli utenti di godersi il cinguettio degli uccelli in un parco senza sentire le persone che parlano o le auto che passano.
Attualmente, l'applicazione dell'UofW utilizza microfoni binaurali per catturare la posizione in tempo reale dei suoni esterni, prima di inviare i suoni filtrati alle cuffie. Poiché questo software funziona su smartphone, la loro applicazione può sfruttare CPU più potenti di quelle presenti nelle cuffie, tuttavia è solo questione di tempo prima che le cuffie a cancellazione di rumore siano dotate di udito semantico integrato.


Fonte(i)
Università di WashingtonACM, e Scuola Paul G. Allen (YouTube)
9 novembre 2023
La nuova tecnologia AI per cuffie a cancellazione del rumore permette a chi le indossa di scegliere quali suoni sentire
Stefan Milne
Notizie UW
Chiunque abbia usato cuffie a cancellazione del rumore sa che sentire il rumore giusto al momento giusto può essere vitale. Qualcuno potrebbe voler cancellare i clacson delle auto quando lavora in casa, ma non quando cammina per strade trafficate. Tuttavia, le persone non possono scegliere quali suoni cancellare con le loro cuffie.
Ora, un team guidato da ricercatori dell'Università di Washington ha sviluppato algoritmi di apprendimento profondo che consentono agli utenti di scegliere quali suoni filtrano attraverso le loro cuffie in tempo reale. Il team chiama il sistema "udito semantico" Le cuffie trasmettono l'audio catturato a uno smartphone collegato, che cancella tutti i suoni ambientali. Tramite comandi vocali o un'app per smartphone, chi indossa le cuffie può selezionare quali suoni desidera includere tra 20 classi, come sirene, pianti di bambini, discorsi, aspirapolvere e cinguettii di uccelli. Solo i suoni selezionati saranno riprodotti attraverso le cuffie.
Il team ha presentato i suoi risultati il 1° novembre all'UIST '23 di San Francisco. In futuro, i ricercatori prevedono di rilasciare una versione commerciale del sistema.
"Capire il suono di un uccello ed estrarlo da tutti gli altri suoni presenti in un ambiente richiede un'intelligenza in tempo reale che le attuali cuffie di cancellazione del rumore non hanno raggiunto", ha detto l'autore senior Shyam Gollakota, professore dell'UW presso la Paul G. Allen School of Computer Science & Engineering. "La sfida è che i suoni che gli indossatori delle cuffie sentono devono sincronizzarsi con i loro sensi visivi. Non si può sentire la voce di qualcuno due secondi dopo che ci ha parlato. Ciò significa che gli algoritmi neurali devono elaborare i suoni in meno di un centesimo di secondo"
A causa di questi tempi ristretti, il sistema uditivo semantico deve elaborare i suoni su un dispositivo come uno smartphone connesso, invece che su server cloud più robusti. Inoltre, poiché i suoni provenienti da direzioni diverse arrivano all'orecchio delle persone in tempi diversi, il sistema deve preservare questi ritardi e altre indicazioni spaziali, in modo che le persone possano ancora percepire in modo significativo i suoni nel loro ambiente.
Testato in ambienti come uffici, strade e parchi, il sistema è stato in grado di estrarre sirene, cinguettii di uccelli, allarmi e altri suoni di destinazione, eliminando tutti gli altri rumori del mondo reale. Quando 22 partecipanti hanno valutato l'output audio del sistema per il suono target, hanno detto che in media la qualità è migliorata rispetto alla registrazione originale. In alcuni casi, il sistema ha faticato a distinguere tra suoni che condividono molte proprietà, come la musica vocale e il parlato umano. I ricercatori osservano che l'addestramento dei modelli su un maggior numero di dati reali potrebbe migliorare questi risultati.
Altri co-autori dell'articolo sono Bandhav Veluri e Malek Itani, entrambi dottorandi dell'UW presso la Allen School; Justin Chan, che ha completato questa ricerca come dottorando presso la Allen School e ora lavora alla Carnegie Mellon University; e Takuya Yoshioka, direttore della ricerca presso AssemblyAI.
Per maggiori informazioni, contatti [email protected].







