

Intervista | "I nostri grandi core Middle sono migliori del loro esercito di piccoli core" Ben Conrad di AMD parla di alcune delle decisioni di progettazione alla base delle APU Ryzen AI e di ciò che rende Strix Halo

AMD ha avuto un intenso CES 2025 con una serie di annunci di nuovi hardware. Questi includono il Ryzen 9 9950X3D cPU desktop, Ryzen 9 9955HX3D e altre APU della gamma Fireun'occhiata in anteprima a RDNA 4, le nuove APU Ryzen AI serie 300 e 200 e l'ammiraglia Ryzen AI Max Strix Halo.
A margine dell'evento, Vaidyanathan Subramaniam (VS) di Notebookcheck ha incontrato Ben Conrad, Director of Product Management for Premium Mobile Client di AMD, per parlare dei nuovi lanci delle APU Ryzen e di ciò che significano per AMD rispetto alla concorrenza, nonché della direzione che probabilmente prenderà il mercato mobile nei prossimi giorni.
TL;DR: AMD emana ottimismo con Strix Point e Strix Halo
Ecco un rapido riassunto di ciò che abbiamo raccolto dalla nostra interazione con Ben. L'intervista completa segue di seguito:
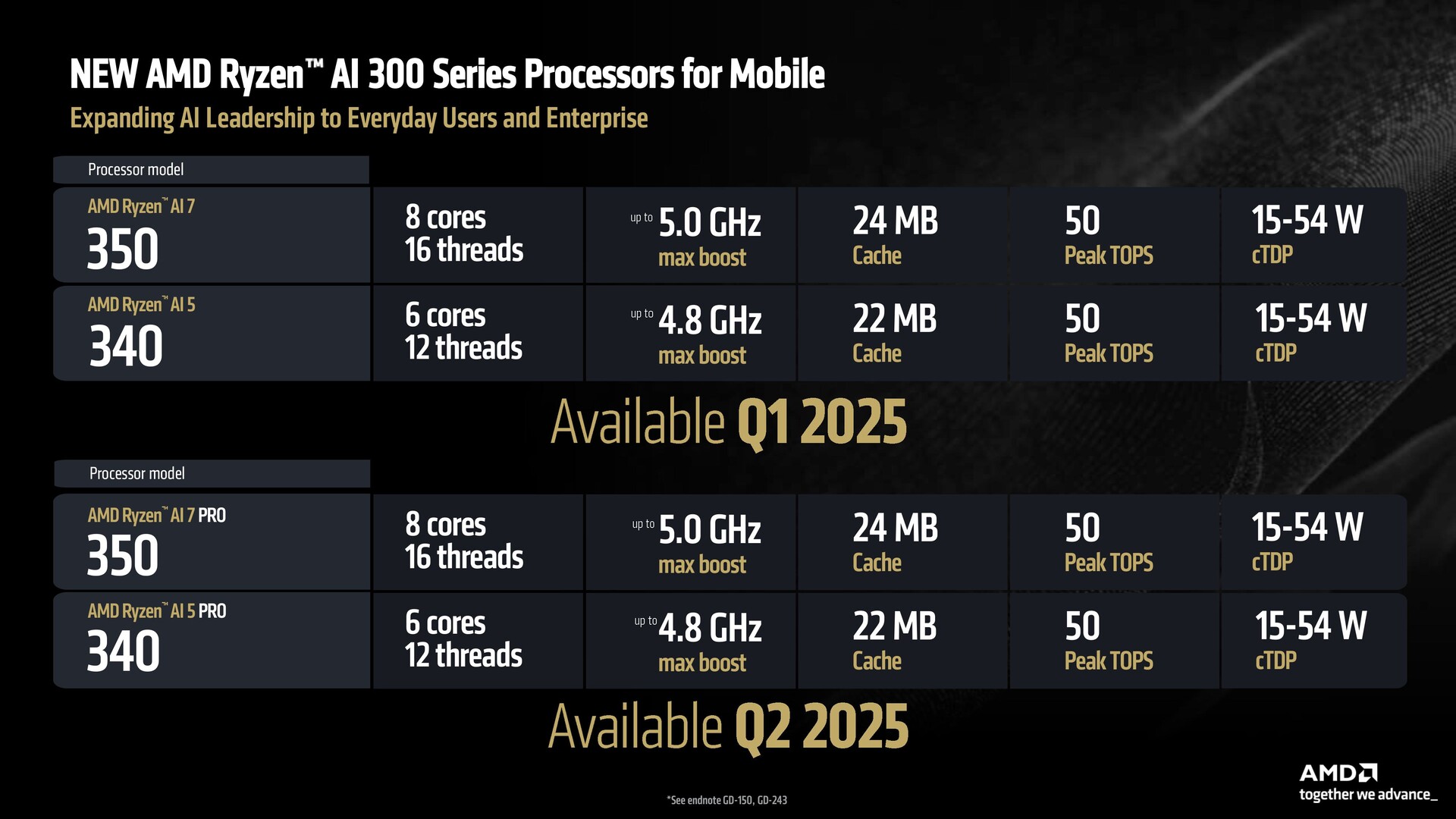
- La Serie Ryzen AI 300 offre un portafoglio completo per gli utenti di tutte le esigenze.
- Tutti i modelli Ryzen AI 300 e Ryzen AI 200 sono compatibili con i precedenti lanci di Strix Point.
- Non sono previsti piani per portare Ryzen AI serie 300 e 200 sui Chromebook.
- L'implementazione "big Middle" di AMD con i core Zen 5 e Zen 5c è una scommessa migliore rispetto all'approccio P-core/E-core della concorrenza, con poche o nessuna penalità di programmazione.
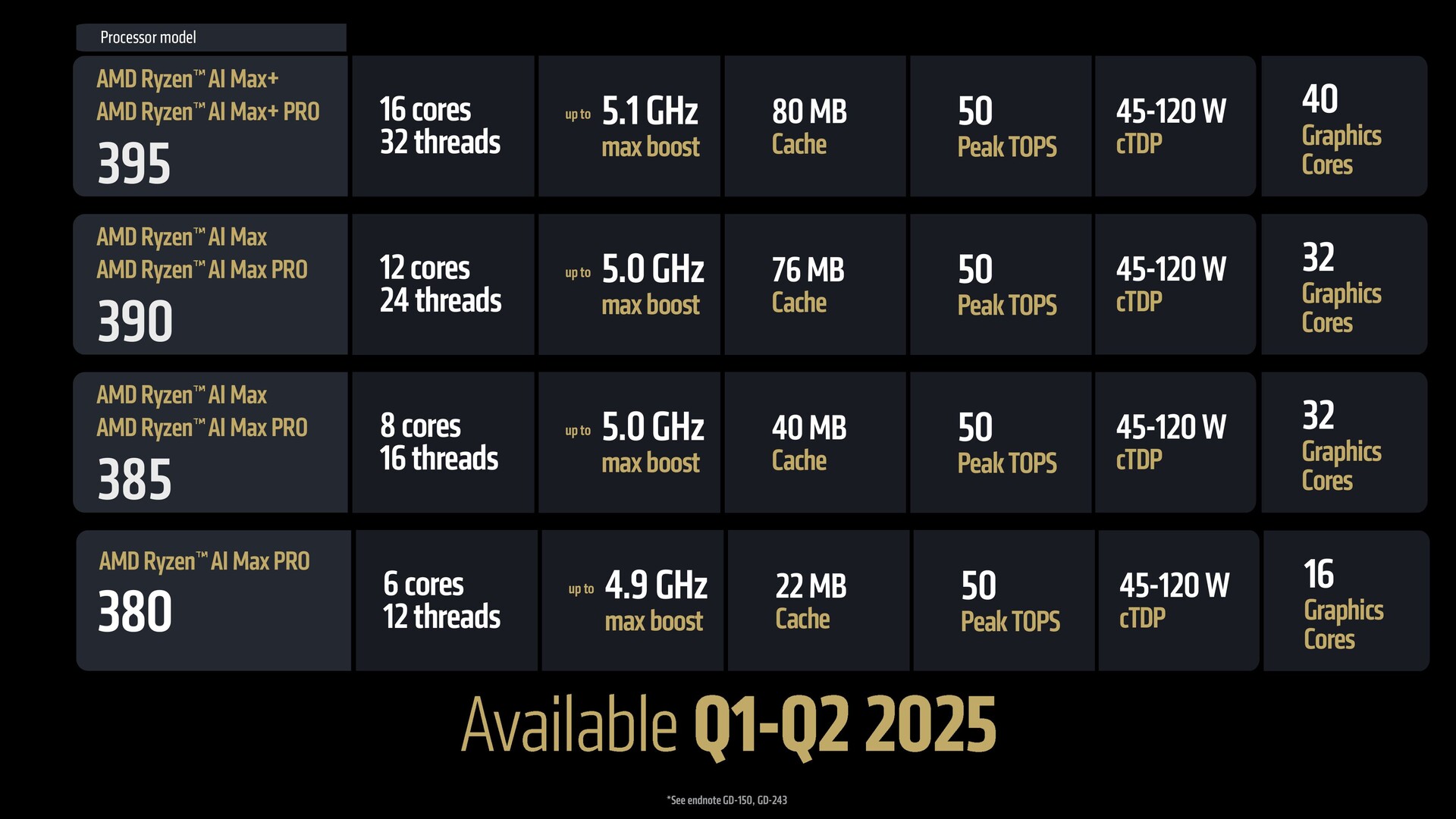
- Strix Halo Ryzen AI Max utilizza gli stessi core Zen 5 "classici" delle parti desktop Ryzen 9000 e Fire Range HX 3D.
- Strix Halo deriva dal desktop e presenta AVX-512, ma sfoggia interconnessioni diverse ottimizzate per la potenza.
- L'RDNA 3.5 di Strix Halo offre una larghezza di banda di memoria equivalente a quella di una RTX 4070, insieme a 32 MB di Infinity Cache. Decisione consapevole di non optare per la memoria on-package.
- Le APU Ryzen AI utilizzano un migliore algoritmo SmartShift ottimizzato per i budget energetici.
- Strix Halo non supporta le dGPU e presenta solo 12 corsie PCIe Gen 4 dalla CPU. Arriverà anche sui mini PC.
- Ryzen AI Max raddoppia la velocità della memoria a LPDDR5-8000 e offre una larghezza di banda simile a quella della RTX 4070.
- Al momento non è previsto un aggiornamento della gamma Dragon, ma non si esclude un futuro aggiornamento della gamma Fire.
- RDNA 4 si concentrerà solo sul desktop, ma le future dGPU e APU mobili sono una possibilità concreta.
- Ci sono piani per portare le funzionalità NPU a punti di prezzo più bassi nel corso del tempo.
L'apparente vantaggio di Ryzen AI
VS: Grazie per il suo tempo, Ben. Cominciamo con la visione di AMD con i nuovi annunci, il suo posizionamento sul mercato e i suoi pensieri sulla concorrenza, in particolare nel segmento dei computer portatili.
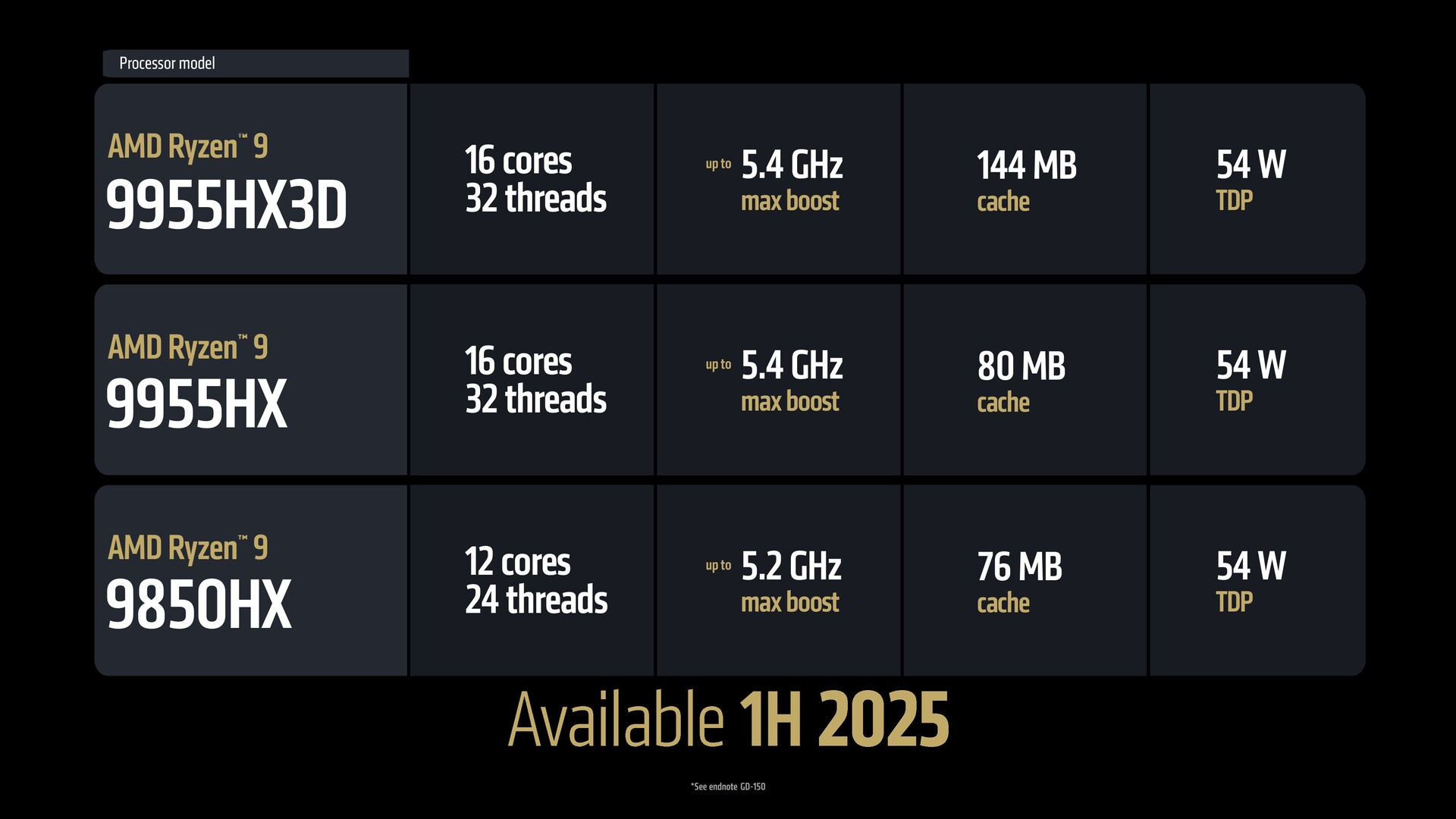
Ben: Il quadro generale è di grande potenziale. Abbiamo Ryzen AI 300, che stiamo estendendo alle SKU Ryzen AI 7 e Ryzen AI 5. Abbiamo anche Ryzen 9 99. Abbiamo anche Ryzen 9 9955HX3D per i giochi e le workstation (portatili) di fascia alta. Poi abbiamo il dirompente Ryzen AI Max per i giochi e le workstation sottili e leggere - una sorta di sistema "best of everything".
Rispetto ai nostri concorrenti, Ryzen AI Serie 300 è un coltellino svizzero. Ha una dGPU collegata, quindi supporta il gaming sottile e leggero. Se apprezza la possibilità di sostituire o aggiungere memoria al suo sistema, supporta l'espansione DDR5 che manca alla concorrenza. Infine, nei sistemi di gioco, offre anche Copilot+.
Tutti questi elementi lo rendono unico. I nostri concorrenti devono presentare più prodotti per coprire la stessa area, mentre noi siamo in grado di fare tutto questo con la Serie 300. E poi facciamo cose fantastiche e pazzesche come Ryzen AI Max, oltre a questo.
Un altro input per i nostri clienti OEM nei computer portatili è che abbiamo una storia di compatibilità dei pacchetti. Tutte le Serie 300, compresa Strix Point che abbiamo lanciato in estate e Kraken Point che stiamo lanciando ora, sono compatibili con i pacchetti e possono essere offerte nello stesso sistema. Anche tutti i Ryzen Serie 200 basati su Hawk Point Zen 4 sono compatibili con i pacchetti.



Quindi, offriamo un sistema a più livelli di prezzo - Copilot+ e AI con enormi capacità grafiche, fino al N meno un prodotto che è ancora ottimo e compete ancora abbastanza bene sul mercato.
Se l'acquirente apprezza le caratteristiche del telaio di quella piattaforma e le vuole a un prezzo (inferiore), abbiamo la Serie 200 e se vuole la prova del futuro dell'AI e tutte le capacità della Serie 300, abbiamo anche quella. C'è flessibilità.
VS: Offrirete dei prodotti ridotti per i Chromebook basati su queste piattaforme, come abbiamo visto con la serie Ryzen 7020C?
Ben: Non abbiamo piani per la Serie 300 nei Chromebook.
VS: E la Serie 200?
Ben: Non credo che abbiamo piani nemmeno per la 200 (per i Chromebook).
L'approccio big Middle di AMD con Zen 5 e Zen 5c
VS: Le SKU di fascia alta sono dotate di un mix di Zen 5 e Zen 5c o sono tutte Zen 5? Quale sarebbe la differenza fondamentale tra questi core?
Ben: Questa è un'ottima domanda. Molte delle SKU della Serie 300 offrono un mix di Zen 5 "classico" e Zen 5 "compatto". I nostri concorrenti utilizzano l'approccio "esercito di piccoli core" in molti dei loro sistemi per ottenere un benchmark multi-threading.
Quindi, ci sono molti piccoli core che potrebbero non essere compatibili con l'ISA, per cui potrebbe esserci una traduzione quando si deve spostare il processo tra i core. Chiamiamo questo ciò che ARM definisce big.LITTLE. Io chiamerei il nostro approccio "big Middle". I core compatti che abbiamo utilizzano lo stesso set di istruzioni e prestazioni molto più elevate rispetto ai core super, super bassi degli altri.
E quindi, in una piattaforma in cui la potenza è limitata, si ha una frequenza di boost massima per un thread. Non è possibile far funzionare contemporaneamente ogni singolo core su quasi tutti i laptop a quella frequenza massima. Quindi, questi core compatti di solito hanno una frequenza massima leggermente inferiore. Ma non c'è quasi nessuna penalizzazione, perché se si trova in uno scenario a un solo thread, può potenziare uno dei core classici.
Questi core compatti si trovano in un'area sicura, quindi possiamo fare cose interessanti con altri IP. Offrono anche una curva di prestazioni diversa nei casi in cui vogliamo che il processo sia su un core a bassa potenza, ma questa è essenzialmente la storia.
Non si tratta di un'enorme traduzione verso e in mezzo, e la cosa fondamentale di questi (core compatti) è che funzionano quasi come un core classico a frequenze più basse e poi, sapete, non scalano alle frequenze più alte, il che non ha un vero impatto sul sistema, perché c'è lo scaling a un thread nei core classici.

Intel Thread Director rispetto all'idea di AMD
VS: Quindi, sta dicendo che il sistema operativo non li vede come un'ISA diversa. Questo significa che, almeno in teoria, molti dei potenziali problemi di programmazione dovrebbero essere alleviati?
Ben: Il sistema operativo li vede come etero-core, ma le penalità per non essere perfetti nella programmazione sono molto più basse.
VS: Ok. Per quanto riguarda l'aspetto della programmazione o il modo in cui si dà priorità al thread su quale core andare, l'utente può avere un frontend per controllarlo? Tanto per dare un contesto, il suo concorrente ha qualcosa chiamato Thread Director. In questo caso, la logica viene decisa dalla CPU. Ma molte volte abbiamo riscontrato che se parcheggia un determinato gioco o un benchmark sui core E, i punteggi si riducono, a meno che non sia in grado di annullare manualmente questo processo con strumenti di terze parti.
AMD ha in programma di dare il controllo agli utenti professionisti che desiderano giocare con i thread, sia nel BIOS che con Ryzen Master? Credo che il controllo dei thread di base sarà sempre presente nel processore. Ma se si tratta di un programma come, ad esempio, Discord, e voglio solo spingerlo sul core Zen 5c, sarebbe possibile?
Ben: Il nostro concorrente ha bisogno di Thread Director a causa dell'enorme differenza tra i core. Quindi, se non si dispone di un buon funzionamento, si ha un'esperienza molto negativa. Ci sono giochi che rilevano il numero di core grandi e che generano thread solo per quei core, a causa della penalità di aggirare tutti gli altri core. Ci sono diversi giochi in circolazione che si vedono effettivamente generare un numero diverso di thread in base al numero di core grandi che valutano dal sistema.


Anche in questo caso, la penalizzazione su AMD è molto più bassa. Credo che si disponga di un paio di funzionalità per impostare l'affinità di thread per aiutare dove si trova. Non sono molto aggiornato su tutte le funzioni software che abbiamo per effettuare la personalizzazione. Probabilmente dovremo ritornare se possiamo cercare di trovare un product manager software interno che possa darvi la risposta migliore.
Per quanto riguarda il contesto, Intel ha preso di mira la mancanza di un meccanismo simile da parte di AMD mentre spiegava a di che cosa si tratta Thread Director.
VS: Nel portafoglio che è stato annunciato ora, abbiamo Zen 5c in qualche SKU di fascia alta? Il Ryzen AI Max, credo, è tutto Zen 5?
Ben: Esatto, il Max è tutto Zen 5. Ha anche AVX-512, quindi è una caratteristica di livello server che si trova nel Ryzen AI Max con tutti i core classici. Questo è il massimo; abbiamo inserito tutto quello che avevamo, quindi le prestazioni massime, come gli stessi 16 core classici, sono disponibili nel 9950X3D e nel Fire Range 9955HX3D. La stessa capacità è ora scalata in fattori di forma che queste piattaforme possono raggiungere.
VS: Fire Range è essenzialmente solo una parte desktop inserita in un chip per laptop o ci sono altri miglioramenti specifici per i dispositivi mobili? Credo che il 9955HX3D sia a 140 W, mentre il 9950X3D arriva a 170 W?
Ben: Sì, si tratta dello stesso silicio e quindi ha ragione. C'è il binning, c'è il software, c'è la messa a punto, c'è un pacchetto diverso - queste sono le differenze che differenziano il prodotto, ma utilizza la stessa base che alimenta il 9950 sul desktop.
Decisioni di design alla base di Strix Halo Ryzen AI Max
VS: I laptop della gamma Fire non riceveranno il marchio Copilot+, credo, perché non c'è una NPU pubblicizzata su di essi? Per quanto riguarda il lato desktop, se ricordo bene, la dottoressa Lisa Su ha detto durante il keynote che abbiamo AVX-512, che dovrebbe accelerare i carichi di lavoro AI, ma non c'è una NPU dedicata in quanto tale sul desktop.
Ben: Né i desktop né Fire Range hanno NPU dedicate. Crediamo assolutamente che la NPU sia nel futuro. Mi aspetto che le tendenze di AMD e di altri operatori del settore portino le NPU a queste funzionalità. Ma ad oggi, una caratteristica dei desktop e della gamma Fire è che hanno fondamentalmente un attacco dGPU al 100%. Quindi, c'è un'enorme quantità di AI nella dGPU.
Per prima cosa concentriamo la nostra NPU sulle piattaforme UMA. O, come dire, piattaforme che hanno un mix di laptop con vincoli di potenza. Questo è stato il motivo, e abbiamo un'ampia gamma di NPU in tutto questo, credo la migliore di qualsiasi altro fornitore.
VS: Il che mi ricorda che, parlando di UMA, pensa che 256 GB/s dovrebbero essere una larghezza di banda di memoria sufficiente rispetto al silicio di Apple? Questa larghezza di banda è sufficiente per spingere i dati avanti e indietro tra gli IP? E come aggiunta, perché non c'è una memoria on-package per questi dispositivi?
Ben: Allora, Ryzen AI Max utilizza letteralmente il doppio dei chip LPDDR5 della serie Ryzen 300 o dei nostri concorrenti con un bus a 128 bit. Quindi si tratta di chip grandi e il pacchetto diventerebbe gigantesco. Quello che abbiamo sentito dai nostri clienti è che amano la flessibilità di poter acquistare la memoria e prendere le proprie decisioni, senza che noi diciamo che avete due opzioni, questa o quella. Quindi, è stata una decisione di progettazione quella di non includere la memoria nella confezione.
Per quanto riguarda la larghezza di banda, dal momento che abbiamo raddoppiato la larghezza del bus, a velocità LPDDR5-8000, è di 256 giga al secondo. E questo è identico a quello della RTX 4070. Nel punto in cui stiamo cercando di completare, siamo esattamente alla stessa larghezza di banda, quindi assolutamente sì. Se avessimo inserito molta più grafica nell'APU e non avessimo raddoppiato la larghezza di banda della memoria, sarebbe stato estremamente limitato.
Quindi, i nostri architetti non guardano solo a un IP e fanno un numero più alto. Bisogna considerare l'intero sistema, assicurarsi di avere la larghezza di banda e la potenza. Abbiamo 32 MB di Infinity Cache, una sorta di cache di livello 4 sul chip. È molto simile alla Infinity Cache della grafica Radeon.
VS: Questa Infinity Cache si trova tra il Radeon 8060S e il CCD?
Ben: Questa cache si trova tra il resto del chip e l'interfaccia di memoria. Quindi, è fondamentalmente una cache di ultimo livello simile al meccanismo Infinity Cache delle nostre dGPU, dove si trova tra la GPU e la memoria GDDR6.
VS: Pensa che Strix Halo possa essere utilizzato anche in altri fattori di forma, come un mini PC?
Ben: Assolutamente sì. Abbiamo un paio di desktop di piccolo formato qui (al CES). Sono sorpreso da quante persone e OEM siano entusiasti di questo piccolo fattore di forma.

VS: Che tipo di interconnessione c'è tra la CPU e la GPU RDNA 3.5 in Ryzen AI Max? Abbiamo qualcosa sulla falsariga di Infinity fabric e SmartShift?
Ben: L'interconnessione, internamente la chiamiamo DDR SSP. Devo capire se il marchio interno è diverso da quello utilizzato nel chip desktop, perché ottimizziamo l'interconnessione per la potenza. Quando si tiene in mano il die di Strix Halo, si scopre che i CCD sono molto vicini al die di I/O. E per questo motivo siamo stati in grado di ottimizzare l'interconnessione per l'alimentazione. Per questo motivo siamo stati in grado di risparmiare diversi Watt di energia, che è il punto centrale della costruzione di Strix Halo, che è davvero a basso consumo per alte prestazioni. Quindi, si tratta di un'interconnessione diversa e non si tratta dello stesso silicio CCD dei nostri chip desktop.
Con SmartShift, c'è un'APU e una dGPU come chip separati, che si scambiano energia tra i due. Rilevando che la dGPU si sta esaurendo, si dice: "Assegniamo questa potenza a questo". Le APU hanno utilizzato SmartShift - la nostra tecnologia SmartShift è basata sul software e si trova a livello del firmware tra questi due chip.
Le nostre APU fanno effettivamente lo SmartShift, condividendo la potenza tra gli IP a livello hardware, perché sono un unico pacchetto. Le nostre APU hanno sempre avuto, come dire, qualcosa di ancora migliore, un pensiero ancora più veloce, che prende la decisione molte più volte al secondo su dove deve andare l'energia.
Quindi, sì, in effetti non l'abbiamo marchiato (come SmartShift) in Ryzen AI Max, ma è un aspetto intrinseco all'hardware di un'APU, che è già avvenuto.
VS: E questo si ripercuote su tutte le APU dello stack?
Ben: Assolutamente. Ogni singola APU assegna la potenza a ciò che è necessario. Se c'è una richiesta sia sulla dGPU che sui core, si guarda a quello che ha più richiesta e si alloca lì.
VS: Su questo aspetto, un OEM può utilizzare Ryzen AI Max e offrire comunque una dGPU, ad esempio una dGPU Radeon?
Ben: Ryzen AI Max non supporta le dGPU collegate. Dato che abbiamo già un'APU di classe dGPU, non c'è davvero alcun motivo. Non è possibile, ad esempio, fare il CrossFire, quindi non ha senso accenderle contemporaneamente. Onestamente, perché un OEM dovrebbe acquistare questa soluzione e poi cercare di aggiungere una dGPU, dato che ora si trova in una forma simile a quella di un fattore di forma da gioco esistente.
VS: In questo caso, come utilizzerebbe al meglio le corsie PCIe della CPU? Credo che molte corsie sarebbero libere, dato che la maggior parte dei design (sottili) hanno a malapena una o due SSD e gli OEM tendono a non offrire comunque la possibilità di espansione dell'archiviazione in questi telai, quindi non si utilizza l'intera larghezza di banda PCIe.
Ben: C'è il PCIe Gen 4 su questi chip. Ryzen AI Max offre 12 corsie di PCIe Gen 4, mentre le nostre APU tipiche che hanno una dGPU collegata hanno da 16 a 20 corsie. Quindi, il motivo per cui l'abbiamo ridotto è che di solito si utilizzano circa otto corsie per la dGPU. Dal momento che non abbiamo una dGPU collegata, 20-8 diventano 12. Vogliamo essere in grado di supportare due SSD e un paio di altri I/O, e credo che alcuni dei nostri clienti di workstation ne approfitteranno.
VS: Quindi, una possibilità potrebbe essere quella di indirizzare l'USB4 verso questo dispositivo invece di andare al chipset?
Ben: Dovrei verificarlo. Di solito, in questo piccolo fattore di forma, non c'è un chip bridge PCIe o altro. Si vuole semplicemente utilizzare l'APU per ottenere quel dimensionamento.
Nomenclatura dei prodotti e prospettive future
VS: Sono in arrivo anche nuovi chip Dragon Range Refresh?
Ben: Credo che sia improbabile. Non credo che annunceremo nulla della famiglia Dragon Range in questo momento.
VS: Questo significa che continuerete a vendere i chip che avete venduto lo scorso anno?
Ben: Certamente. Anche se una APU non rientra nella nostra attuale tabella di marcia, se gli OEM continuano a costruire sistemi con i progetti precedenti, assolutamente sì. C'è una lunga storia di vendita di prodotti esistenti a distanza di anni. Non è come progettare un nuovo sistema con questo, ma ehi, il sistema sta vendendo benissimo, quindi sta andando bene, e continuerà.
VS: Questo implicherebbe, anche se non è ufficiale, che lei non esclude del tutto la possibilità di vedere chip rinnovati con un nuovo schema di nomi o qualcosa del genere?
Ben: Sa, nei nostri schemi di denominazione, vogliamo che i clienti possano decidere facilmente. A volte consideriamo un aggiornamento come la Serie 200. Si tratta in gran parte di un aggiornamento della linea di prodotti. Non è una novità assoluta. Ma il motivo è che è davvero strano per un cliente avere una Serie 300, una Serie 8000, e chiedersi... aspetti che 8000 sia meno di 300, non ha senso! Quindi questo è parte del motivo.
Nella generazione attuale, vogliamo che il marchio sia coerente e facilmente comprensibile. Ora si tratta di un marchio a tre cifre, il numero più alto è migliore. Quindi, 200 è Hawk, e poi, sa, in 300 c'è Strix Point e Kraken, e il Max in alto. Si tratta di una strategia di marchio coerente. Credo che faremo qualcosa di simile anche per il lancio del Fire Range.
VS: Voglio dire, ammetto che non è sempre facile pronunciare l'intero nome del chip in un colpo solo "Ryzen.AI.9.300.Max.Plus"!
Ben: Penso che molti di noi, sai, beh, lasciami dire che nel settore AMD abbiamo così tanti prodotti, quindi è difficile. Vogliamo che qualcosa sia coerente, che sia differenziato, che i consumatori lo sappiano. Quindi, onestamente, quando un consumatore entra nei negozi, credo che veda Copilot+ e 9, 7, 5, 3. Probabilmente... è sufficiente. Non guardano il numero esatto del modello.
Siamo tutti (riferendosi agli appassionati) molto esperti di baseball, giusto? Vogliamo conoscere ogni dettaglio, quindi credo che questo faccia parte delle differenze.
VS: E vede prospettive per i portatili RDNA 4 in futuro? Purtroppo, il numero di SKU di computer portatili basati su dGPU AMD è stato piuttosto anemico.
Ben: La nostra attuale strategia grafica si concentra sul mercato desktop con RDNA 4. Quindi, credo che in futuro vedrete prima questi tipi di prodotti. Certamente, RDNA 4 e le tecnologie grafiche future arriveranno nel settore mobile, sia nelle APU che nei prodotti futuri.
VS: Probabilmente questo è futuristico, ma abbiamo sentito dire che RDNA e CDNA si combineranno insieme.
Ben: Sì, si tratta di un progetto a lungo termine per unificare i due, e personalmente ne sono molto entusiasta, perché il focus ML è in realtà la direzione in cui il mercato dei clienti andrà a lungo termine. Quindi, se tutti andassero nella stessa direzione, credo che sarebbe davvero positivo.
VS: Ok, un'ultima domanda, e anche questo è stato uno dei miei crucci. Nella fascia bassa penso che ci sia molto spazio perché non tutti vogliono un chip di fascia alta per le loro esigenze. Cose come l'editing di base a 1080p, la maggior parte dei chip è in grado di farlo in questo momento. Perché AMD non si concentra, ad esempio, su Ryzen 3, perché offre una NPU da 50 TOPS in tutto lo stack. Perché non fare lo stesso sul lato GPU? O magari sfruttare la NPU stessa e offrire un prodotto entry-level su cui è possibile eseguire la creazione di contenuti di base e altro.
Oppure si potrebbe scendere ancora più in basso. Ad esempio, c'era qualcosa chiamato Ryzen Embedded R1606Gche abbiamo visto in uno o due mini PC.
Ben: Quindi, abbiamo in programma di portare la NPU a punti di prezzo migliori sul mercato nel corso del tempo. Credo che anche il settore si stia dirigendo in questa direzione. Quindi, vogliamo assolutamente offrire a tutti i consumatori un PC Copilot+, un'esperienza AI abilitata dalla NPU. Bisogna solo considerare gli aspetti economici e i punti di prezzo che questi comandano, ed è solo un'area di silicio, ok, cosa possiamo inserire.
Ad esempio, potremmo ridurre l'interfaccia di memoria a 64 bit. Ma cosa comporta per il resto del sistema? Quanti core sono il minimo per questo tipo di prestazioni? Credo di poter dire che negli ultimi due anni, la NPU non è più un elemento secondario. È una delle tre trinità di IP su cui dobbiamo concentrarci. Quindi, stiamo assolutamente cercando di ridimensionare questi tre aspetti in tutti i segmenti.
Fonte(i)
Proprio





