

Approfondimento dell'architettura AMD RDNA 4: Un design monolitico a 64-CU con miglioramenti a tutto tondo per l'elaborazione, la codifica-decodifica dei media, il ray tracing e l'intelligenza artificiale

AMD ha offerto una un'anticipazione rDNA 4 al CES 2025 e ha confermato l'arrivo di Radeon RX 9070 XT e RX 9070, ma non ha offerto nemmeno un'osservazione di passaggio sulla nuova architettura durante il keynote vero e proprio.
L'azienda, tuttavia, ha affermato che maggiori informazioni su RDNA 4 e sulle nuove GPU Radeon sarebbero arrivate presto, ed eccoci qui.
Oggi, AMD ha svelato RDNA 4 e le nuove GPU della serie Radeon RX 9070. La serie RX 9070 sarà ufficialmente disponibile nei negozi al dettaglio a partire dal 6 marzo, mentre le recensioni delle prestazioni arriveranno un giorno prima.
AMD RDNA 4: ritorno a un design monolitico
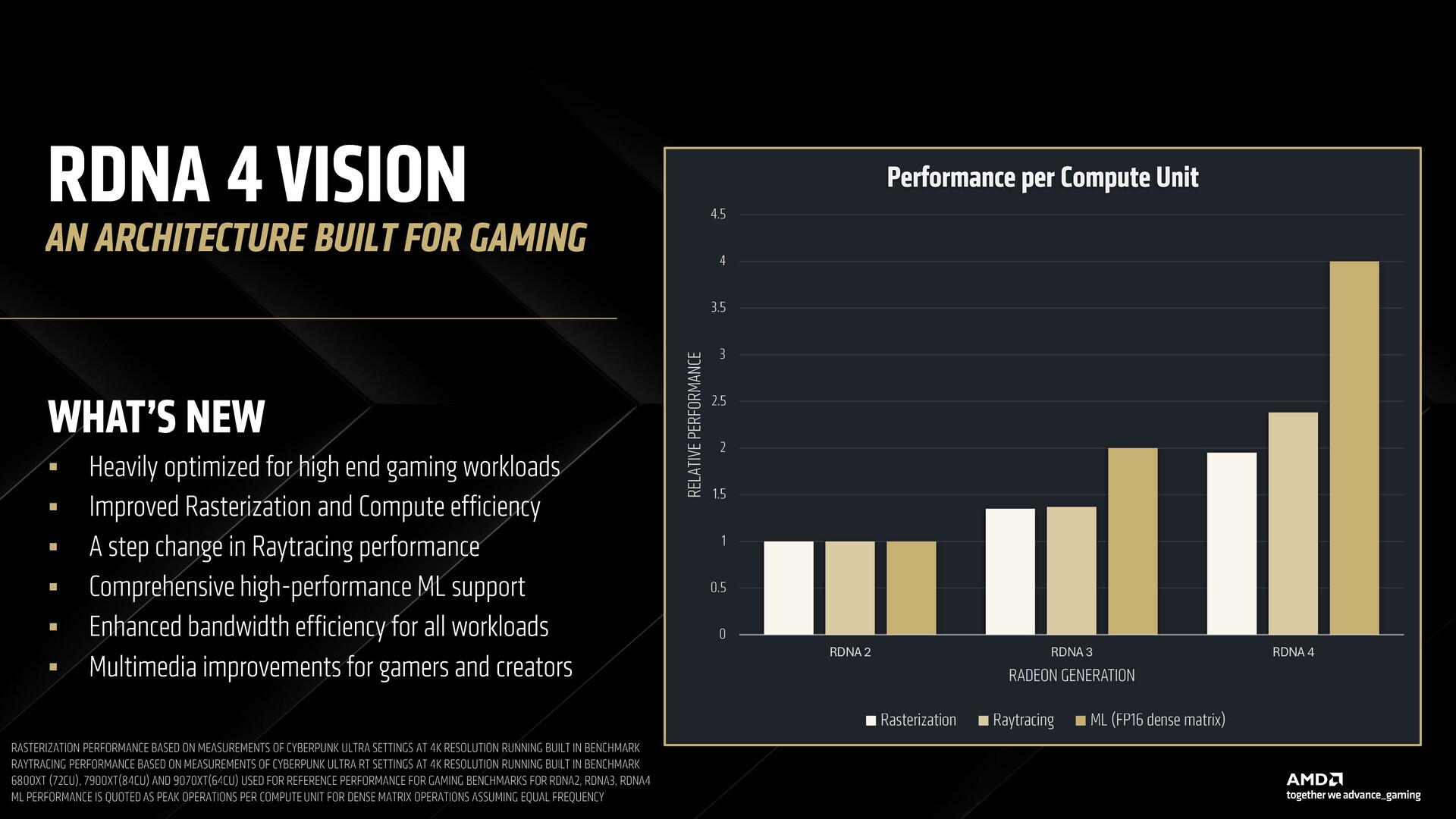
RDNA 4 si basa sugli obiettivi che AMD si era prefissata con RDNA 3. Secondo AMD, RDNA 4 è progettato per soddisfare i carichi di lavoro di gioco più pesanti, con un'attenzione particolare alle prestazioni e all'efficienza raster migliorate.
Ci sono poi i consueti miglioramenti alle pipeline di ray tracing, oltre a una rinnovata attenzione alle funzionalità AI e alla codifica/decodifica dei media.
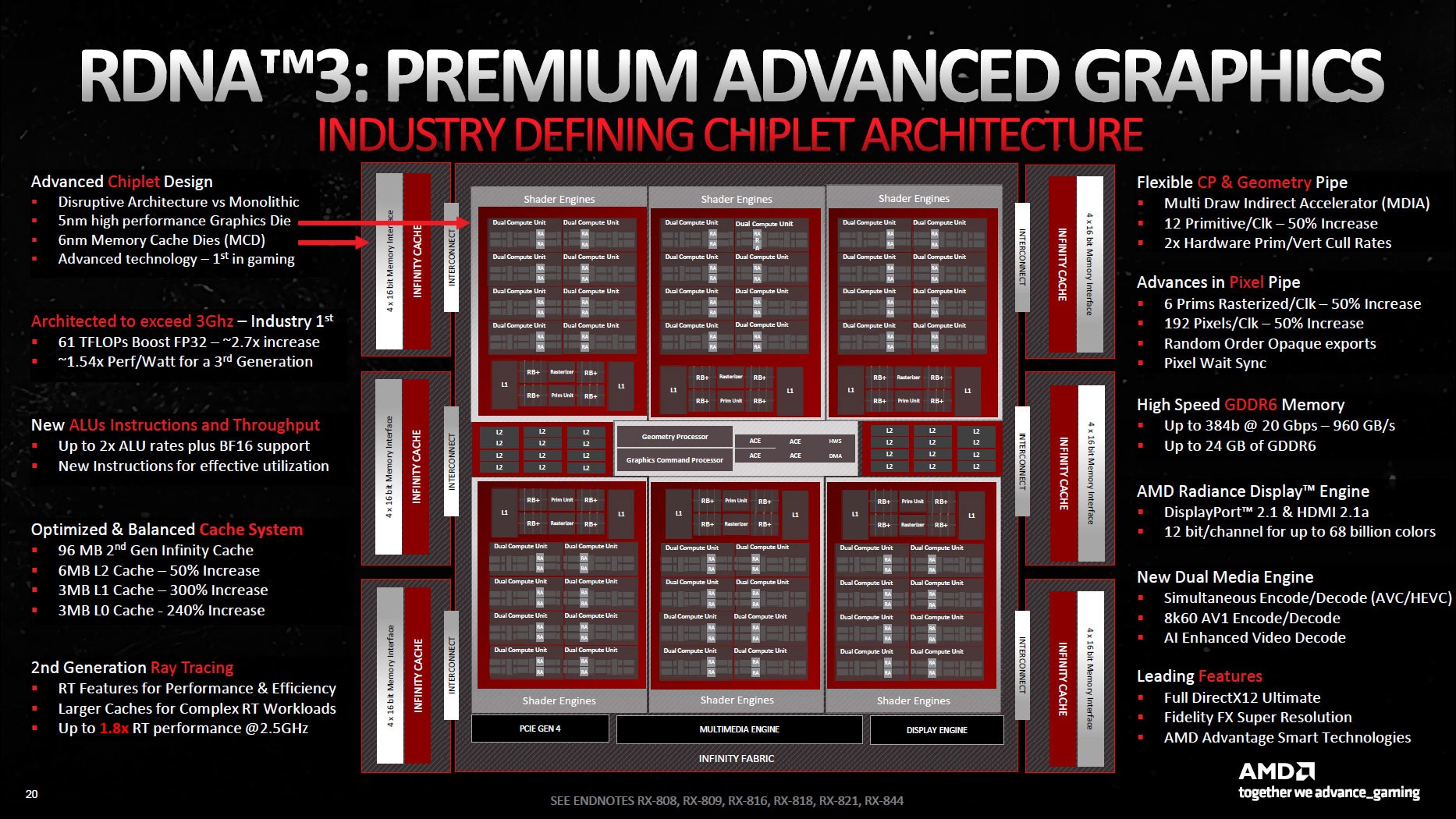
RDNA 3 ha visto l'avvento di un design a chiplet per le GPU, ispirandosi ai processori Ryzen. In questo caso, abbiamo assistito alla separazione dei die della memoria cache (MCD) dal die di calcolo grafico (GCD).
Con RDNA 4, tuttavia, AMD torna al tradizionale design monolitico. I componenti sono essenzialmente gli stessi, ma non ci sono interconnessioni MCD-GCD, poiché la memoria e l'elaborazione sono ora interfacciate direttamente dalla Infinity Cache.
La GPU RDNA 4, la Radeon RX 9070 XT in questo caso, presenta quattro motori shader con otto processori workgroup (WGP) ciascuno. Ogni WGP è composto da un totale di otto unità di calcolo (CU) per un totale di 64 CU.
AMD afferma che le nuove unità di calcolo sono ora più capaci che mai, consentendo un ray tracing migliorato, un throughput di picco raddoppiato, il supporto delle più recenti capacità di accelerazione matriciale con un più ampio supporto di formati numerici.
La novità della CU RDNA 4, che abbiamo già visto con i core Tensor nell'architettura Ampere di Nvidia, è il supporto della sparsità strutturata, che consente di velocizzare le operazioni matriciali, soprattutto nei casi in cui molti pesi sono pari a zero.
Vediamo anche i miglioramenti del sottosistema di memoria. La cache L2 passa da 6 MB in RDNA 3 a 8 MB in RDNA 4, mentre la Infinity Cache viene aggiornata alla terza generazione, ma scende a 64 MB da 96 MB in RDNA 3.
AMD continua a fare affidamento sulla memoria GDDR6 con la nuova generazione. Sia la RX 9070 XT che la RX 9070 offrono un'interfaccia di memoria GDDR6 da 16 GB a 384 bit, con un clock di 20 Gbps, per una larghezza di banda effettiva di 640 GB/s. Si tratta di una larghezza di banda molto inferiore rispetto ai 960 GB/s offerti da RDNA 3, ma AMD afferma che le specifiche della memoria video di RDNA 4 sono state scelte con cura per supportare i titoli attuali e futuri.
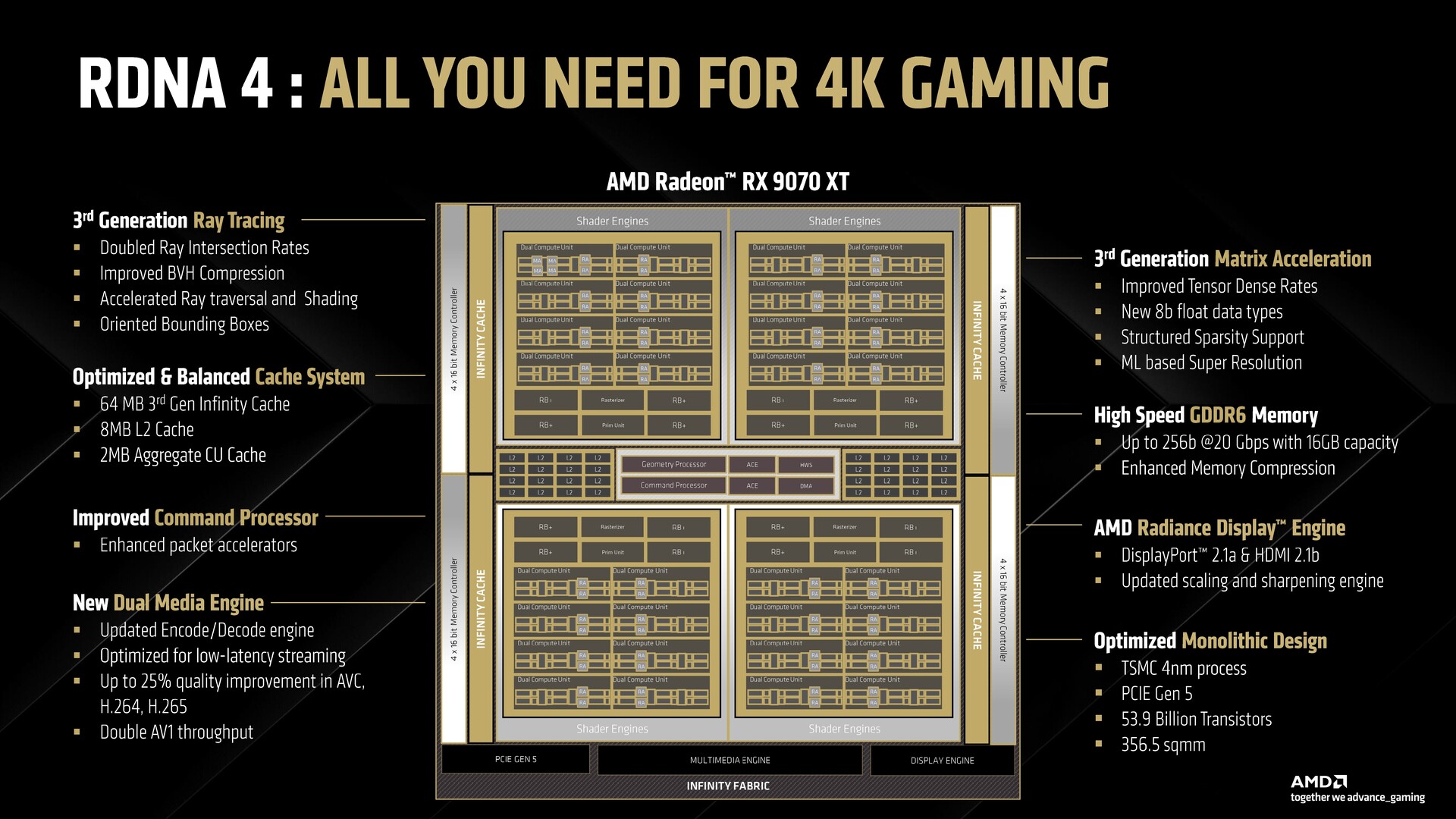
Motore multimediale migliorato e supporto hardware flip metering
La codifica video è stata una delle principali insidie di RDNA 3 e AMD promette miglioramenti significativi a questo proposito. L'azienda promette grandi miglioramenti nella codifica H.264 e AV1 e meno artefatti di blocco per la stessa quantità di dati.
I miglioramenti si estendono anche alla decodifica video, con una riduzione del consumo energetico e un aumento delle prestazioni durante la decodifica di formati come AV1 e VP9.
Il Radiance Display Engine ora consuma molta meno energia nelle configurazioni FreeSync a doppio monitor. È nuovo anche il supporto per l'hardware flip queue in Windows Display Driver Model (WDDM) 3.0 per la riproduzione video.
Questo libera le risorse della CPU scaricando la programmazione dei fotogrammi sulla GPU. La tecnologia di generazione multi-frame (MFG) nelle GPU Nvidia Blackwell si basa anche sulla misurazione hardware dei flip.


Uno sguardo all'unità di calcolo RDNA 4
All'inizio, la struttura di un CU RDNA 4 non è molto diversa da quella che abbiamo visto con RDNA 3. Tuttavia, ci sono miglioramenti in termini di prestazioni ed efficienza in ciascuno dei componenti del CU.
Le operazioni WMMA (Wave Matrix Multiply Accumulate) sono state migliorate per soddisfare i requisiti del nuovo hardware. Le unità Scaler sono state aggiornate per gestire le operazioni Float32. Lo scheduler può dividere ed elaborare un carico di lavoro di calcolo di grandi dimensioni in barriere divise e nominate.
AMD ha dichiarato che RDNA 4 è costruito per soddisfare le nuove tecniche di rendering che gli sviluppatori utilizzano nei giochi di oggi. Mentre l'upscaling è stato in voga, un path tracing efficace richiede l'accelerazione ML come parte del processo di rendering stesso e non come un ripensamento.
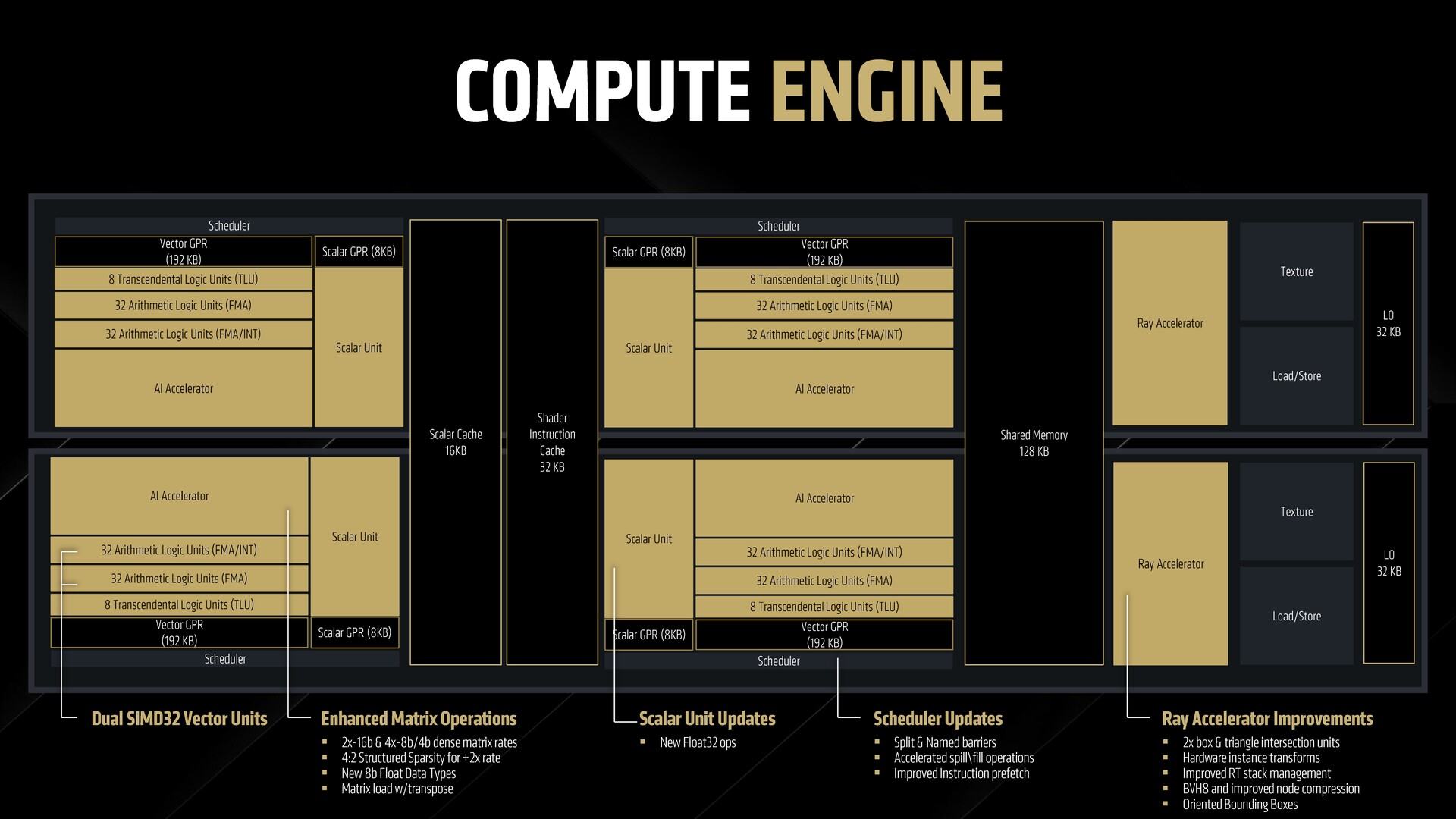

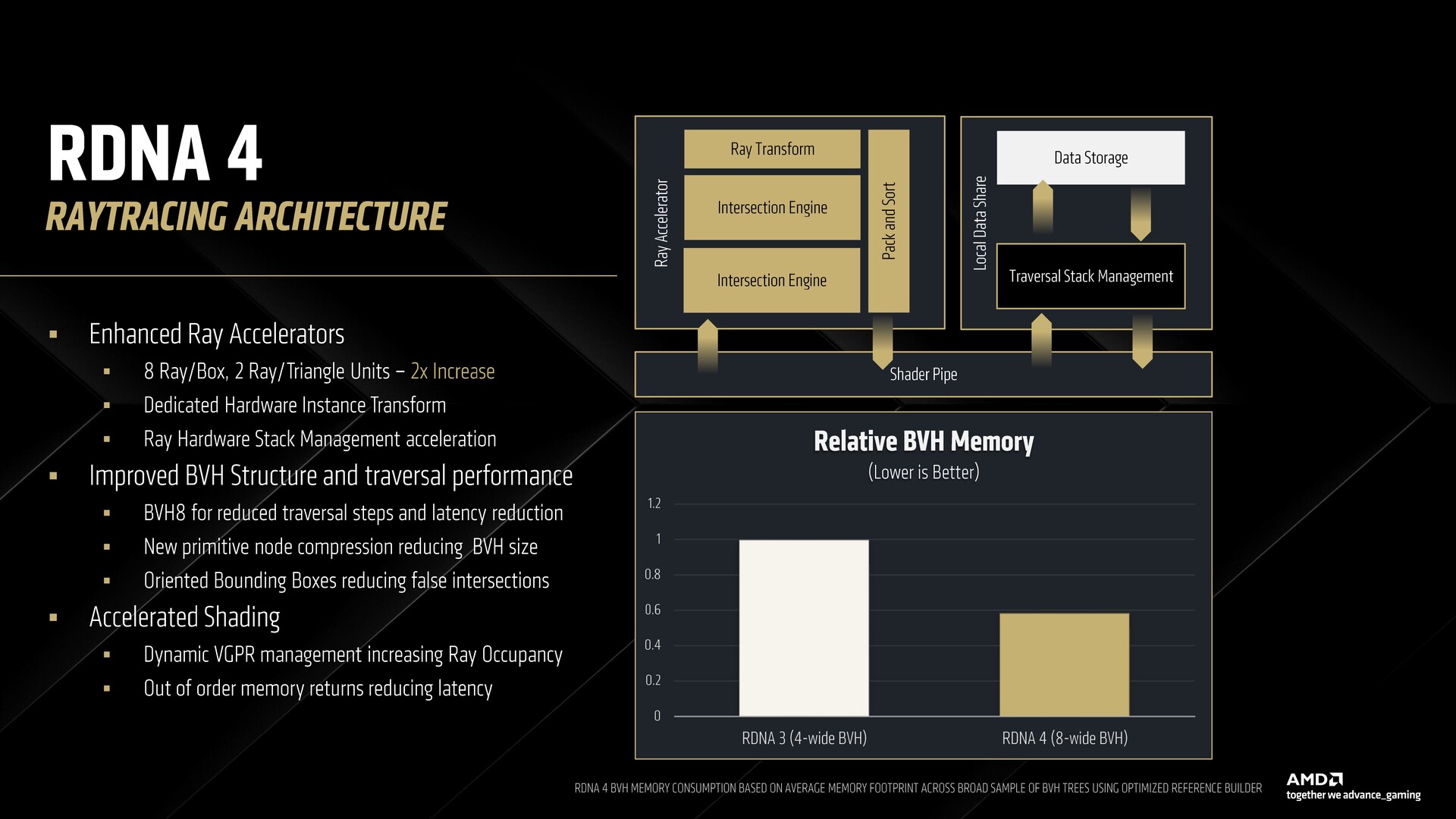
Acceleratori di raggi in RDNA 4
RDNA 4 offre 64 acceleratori di raggi di terza generazione nella RX 9070 XT. La struttura di un acceleratore di raggi in RDNA 4 è simile a quella di RDNA 3, ma include un motore di intersezione aggiuntivo per un numero doppio di unità ray box e ray triangle.
C'è anche una trasformazione del raggio hardware dedicata che allevia la necessità di usare le istruzioni shader per fare il lavoro, riducendo così al minimo l'overhead della traversata del raggio. Una memoria di 128 KB in ogni dual CU aiuta a contenere lo stack di raggi per un'efficiente operazione di push e sort.
RDNA 4 introduce il concetto di bounding box orientati (OBB) che allinea i bounding box BVH alla geometria, riducendo al minimo le interazioni false-positive dei raggi in quello che altrimenti è solo spazio vuoto in un box. AMD afferma che questo approccio può migliorare le prestazioni di attraversamento dei raggi fino al 10%.
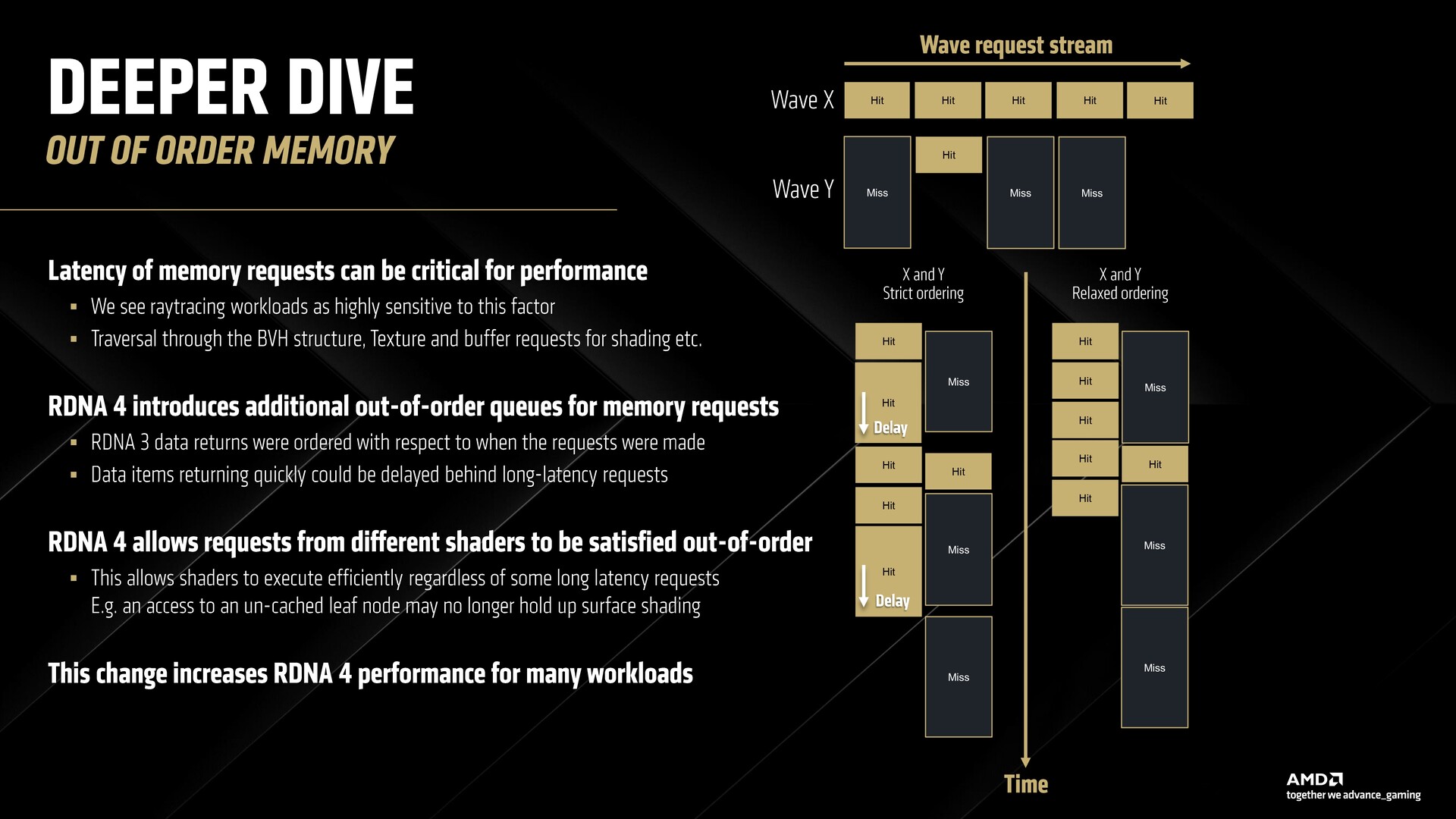
Un'altra novità di questa volta è il supporto per le richieste di memoria fuori ordine rilassate, che riduce in modo efficiente il tempo di attesa per le onde che non hanno raggiunto prima la cache di alto livello. Questo non migliora solo il ray-tracing, ma anche altri carichi di lavoro.
In RDNA 4, gli shader possono allocare dinamicamente i registri che consentono di ospitare più onde in volo con una migliore latenza di memoria.



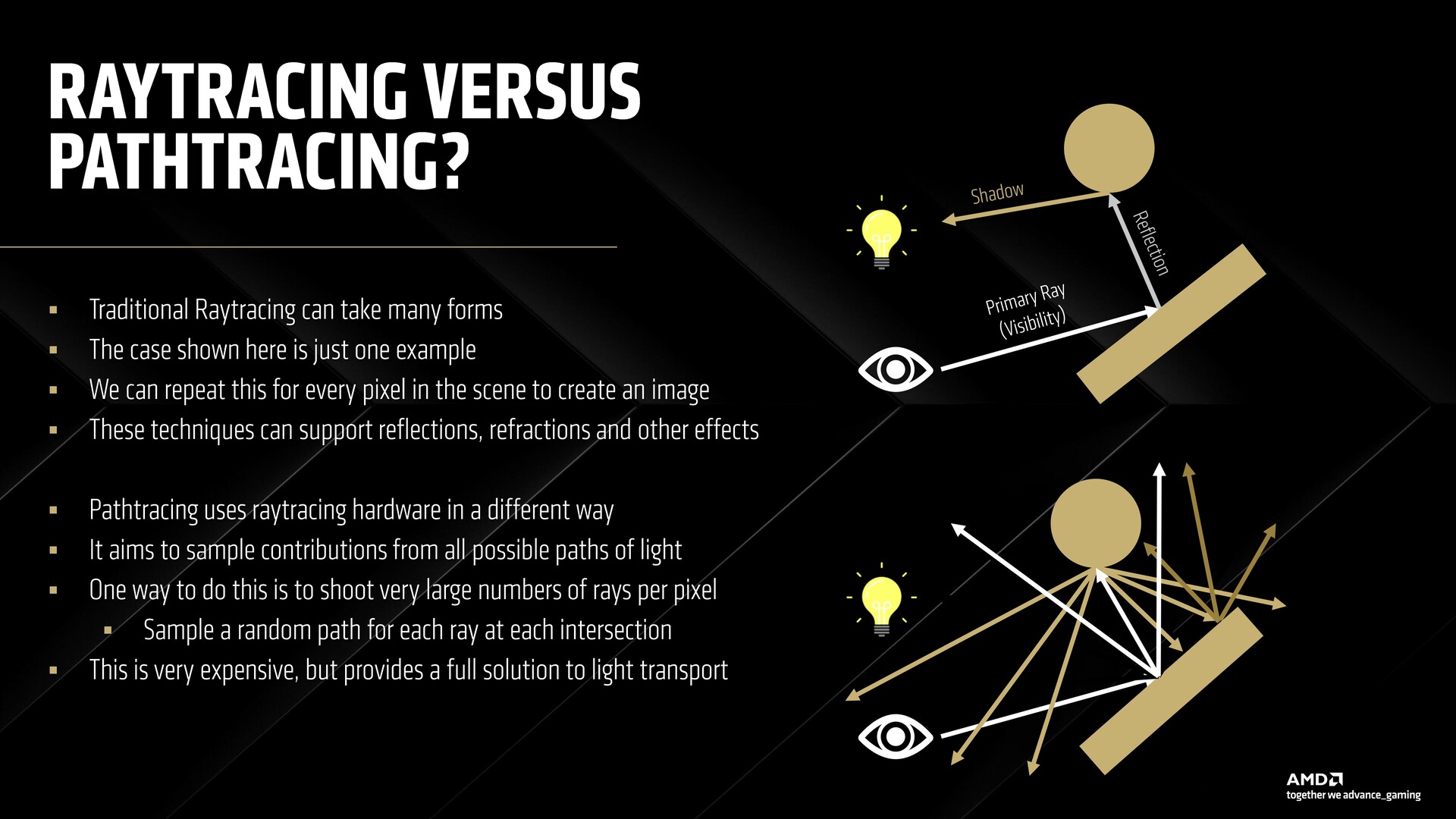
Tracciamento del percorso con RDNA 4
Le schede AMD hanno faticato con il ray tracing in generale, quindi il path tracing sembrava fuori dall'equazione anche con le schede RDNA 3 di fascia alta. RDNA 4 mira a cambiare questa situazione con il supporto per la cache della radianza neurale, insieme a un nuovo modello di supersampling neurale e di denoising.
AMD non ha fornito i numeri esatti delle prestazioni dei titoli abilitati al path tracing, ma dovremmo farcene un'idea durante la recensione di queste schede.




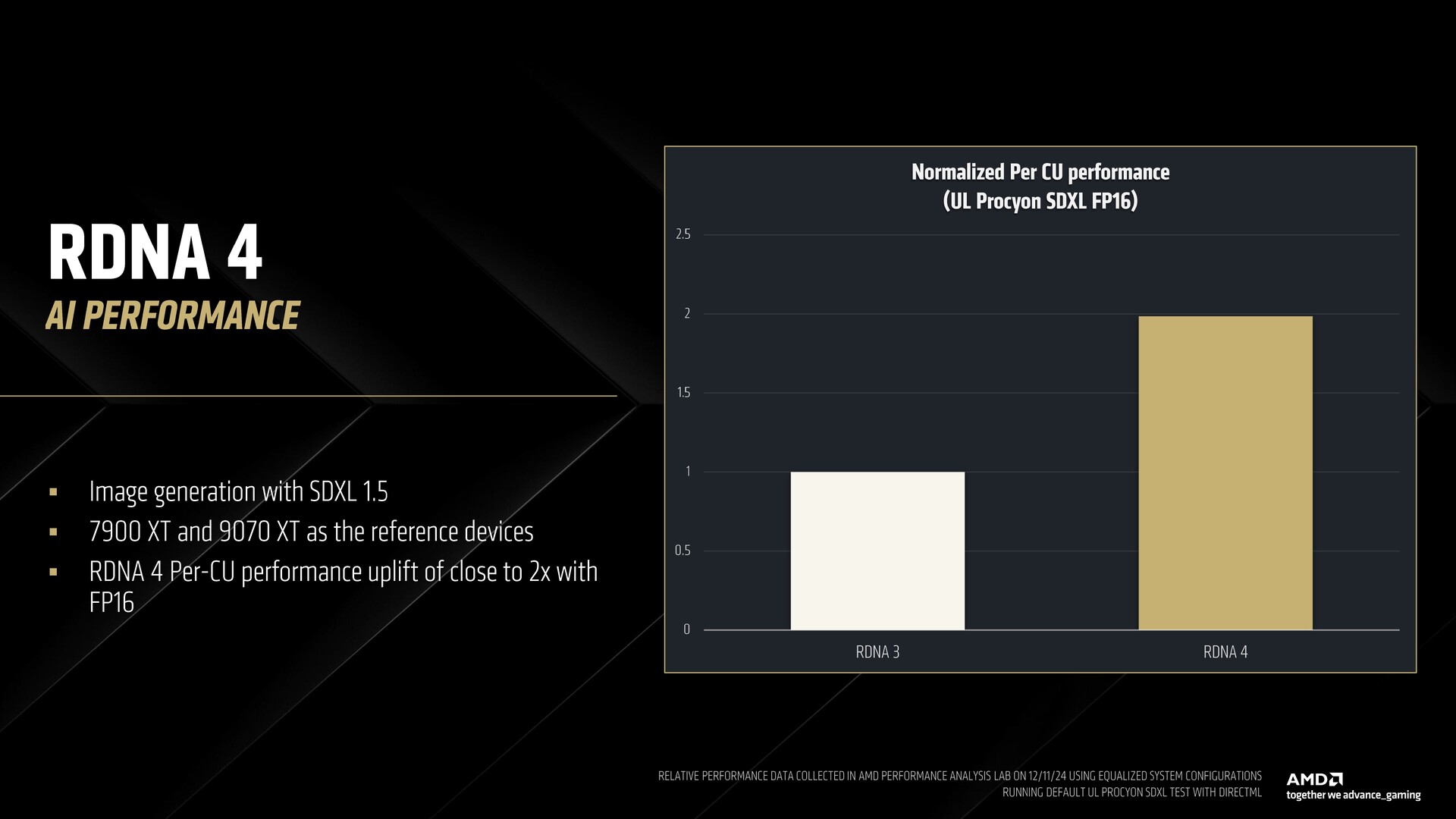
Funzionalità AI costruite su Radeon e Instinct
AMD ha dichiarato che RDNA 4 presenta pipeline matematiche dedicate per l'accelerazione ML, focalizzate su prestazioni elevate con tipi di dati più ristretti. La novità di RDNA 4 è il supporto di FP8 e BF8 per l'inferenza ad alte prestazioni e ad alta precisione.
Dimostrando la generazione di immagini SDXL 1.5, AMD ha mostrato come la Radeon RX 9070 XT basata su RDNA 4 offra il doppio delle prestazioni FP16 per CU rispetto alla RX 7900 XT basata su RDNA 3.
Sfruttando le nuove capacità AI di RDNA 4, c'è FSR 4, che è una pipeline end-to-end addestrata sulle GPU AMD. FSR 4 utilizza FP8 per un uso ottimale della larghezza di banda, delle prestazioni e della potenza.
AMD ha dimostrato miglioramenti fino a 3,7 volte i fps con FSR 4, in combinazione con l'interpolazione dei fotogrammi e Radeon Anti-Lag, mantenendo un'elevata qualità dell'immagine.



Fonte(i)
Briefing per la stampa di AMD











