

Anthropic lancia l'AI più intelligente Claude 3.7 Sonnet che può giocare a Pokémon Rosso come un promettente professionista
Anthropic ha lanciato Claude 3.7 Sonnet, il suo ultimo chatbot AI con competenze avanzate di codifica e pensiero profondo per risolvere richieste complesse e compiti di programmazione utilizzando una finestra di token più ampia da 128K.
Analogamente ad altri recenti rilasci di modelli linguistici di AI di grandi dimensioni da parte di OpenAI e xAI, l'aggiunta del pensiero esteso consente all'ultima AI di Anthropic di dedicare più tempo alla risoluzione di problemi impegnativi prima di rispondere.
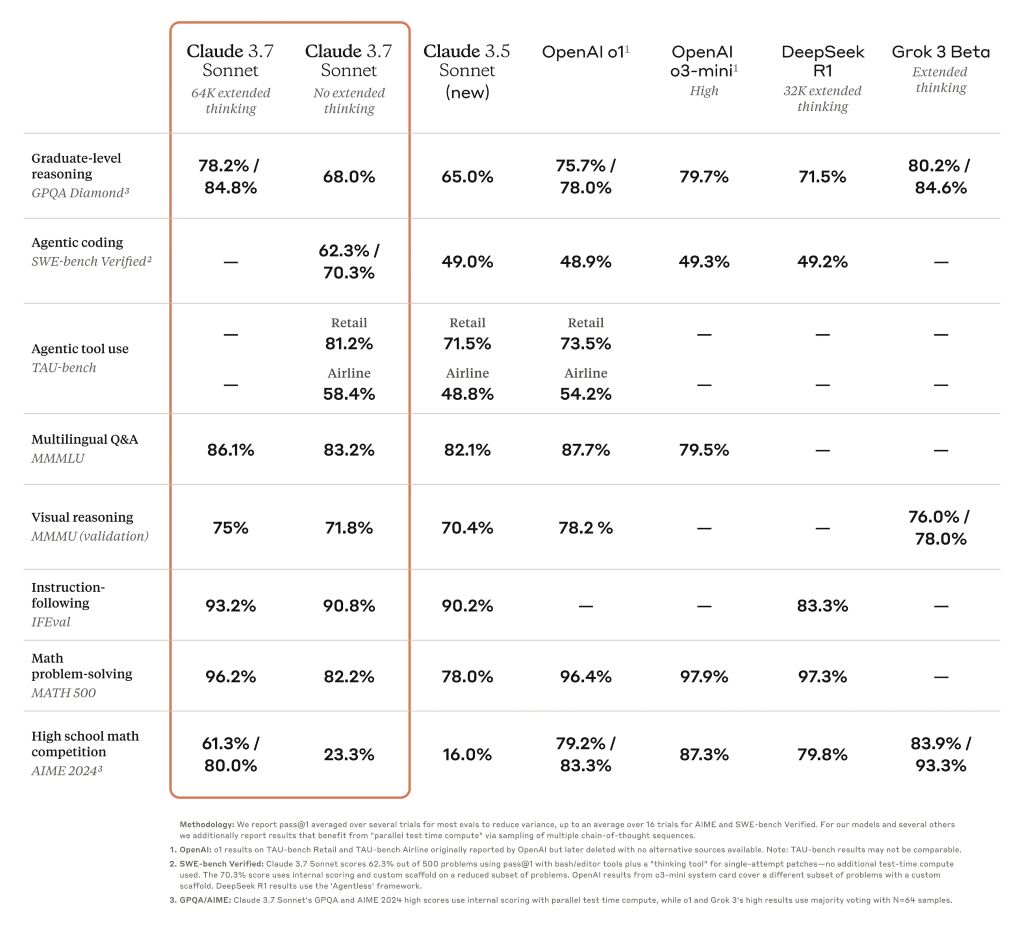
Questo ha elevato le prestazioni di Claude da ritardatario a una delle migliori AI in molti test difficili, come il benchmark di livello dottorale GPQA. Tuttavia, l'aggiornamento non significa che la versione 3.7 sia la migliore IA al mondo, in quanto non è in grado di essere la numero uno in alcuni benchmark rispetto ad altri modelli ad alte prestazioni.
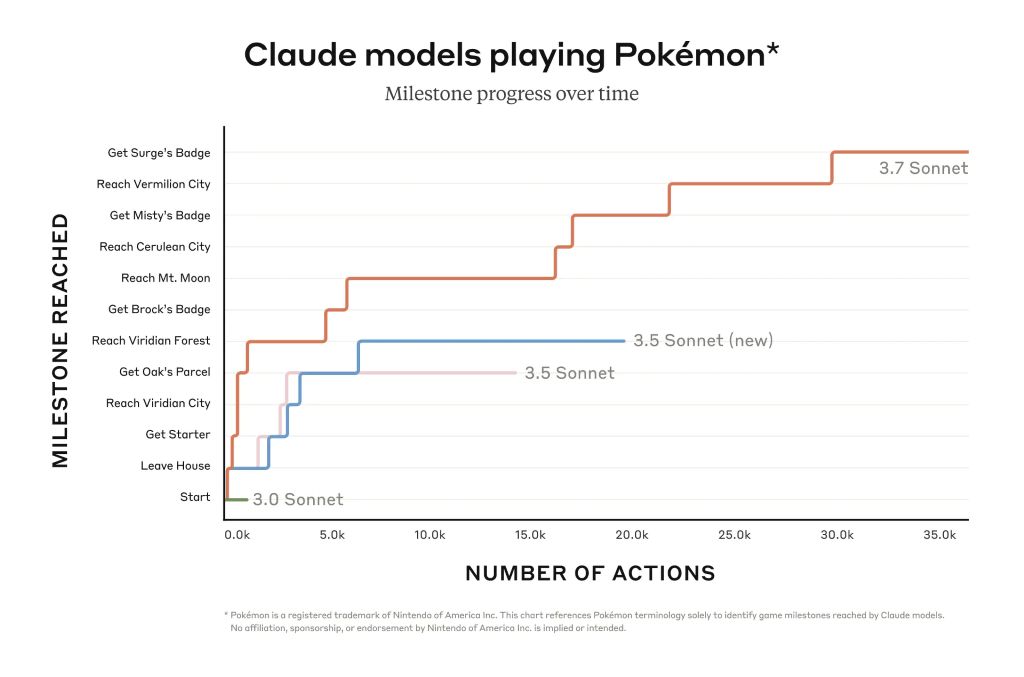
Tuttavia, Claude può avanzare molto di più in giochi come Pokémon Rosso rispetto ai modelli precedenti dell'azienda. Anche i programmatori beneficiano della sua migliore capacità di risolvere i problemi del software del mondo reale e di creare codice. Un'anteprima limitata di Claude Code apre l'accesso a un agente che collabora con il programmatore per modificare, testare e aggiornare basi di codice complesse su GitHub, facendo risparmiare molto tempo ai programmatori.
Un'AI più intelligente significa potenzialmente un'AI più pericolosa. Claude 3.7 Sonnet ha fornito risposte a richieste che violavano le politiche di Anthropic tre volte più spesso di Claude 3.5 durante le valutazioni di sicurezza interne, anche se con un tasso complessivamente ridotto (0,6% delle volte). L'AI è stata anche in grado di infettare una rete di computer di prova e di esfiltrare i dati attraverso metodi di attacco informatico che includevano la riscrittura del codice. La versione pubblica di Claude è dotata di salvaguardie per impedire questo tipo di utilizzo.
I lettori possono utilizzare le funzioni di base di Claude 3.7 Sonnet gratuitamente oggi, mentre le funzioni avanzate come il pensiero esteso richiedono un abbonamento a pagamento.
Fonte(i)
Sonetto Claude 3.7 e Codice Claude
24 febbraio 2025
5 minuti di lettura
Un'illustrazione del ragionamento di Claude passo dopo passo
Oggi annunciamo Claude 3.7 Sonnet1, il nostro modello più intelligente fino ad oggi e il primo modello di ragionamento ibrido sul mercato. Claude 3.7 Sonnet può produrre risposte quasi istantanee o un ragionamento esteso, passo dopo passo, che viene reso visibile all'utente. Gli utenti API hanno anche un controllo a grana fine sulla durata del ragionamento del modello.
Claude 3.7 Sonnet mostra miglioramenti particolarmente forti nella codifica e nello sviluppo web front-end. Insieme al modello, stiamo introducendo anche uno strumento a riga di comando per la codifica agonica, Claude Code. Claude Code è disponibile come anteprima di ricerca limitata e consente agli sviluppatori di delegare a Claude compiti di ingegneria sostanziali direttamente dal loro terminale.
Schermata che mostra l'onboarding di Claude Code
Claude 3.7 Sonnet è ora disponibile su tutti i piani Claude, inclusi Free, Pro, Team ed Enterprise, oltre che su Anthropic API, Amazon Bedrock e Vertex AI di Google Cloud. La modalità di pensiero estesa è disponibile su tutte le superfici, ad eccezione del livello Claude gratuito.
Sia nella modalità di pensiero standard che in quella estesa, Claude 3.7 Sonnet ha lo stesso prezzo dei suoi predecessori: 3 dollari per milione di gettoni di ingresso e 15 dollari per milione di gettoni di uscita, che includono i gettoni di pensiero.
Claude 3.7 Sonnet: Ragionamento di frontiera reso pratico
Abbiamo sviluppato Claude 3.7 Sonnet con una filosofia diversa rispetto agli altri modelli di ragionamento presenti sul mercato. Proprio come gli esseri umani utilizzano un unico cervello sia per le risposte rapide che per la riflessione profonda, crediamo che il ragionamento debba essere una capacità integrata dei modelli di frontiera, piuttosto che un modello completamente separato. Questo approccio unificato crea anche un'esperienza più fluida per gli utenti.
Claude 3.7 Sonnet incarna questa filosofia in diversi modi. In primo luogo, Claude 3.7 Sonnet è sia un normale LLM che un modello di ragionamento in uno: può scegliere quando vuole che il modello risponda normalmente e quando vuole che pensi più a lungo prima di rispondere. Nella modalità standard, Claude 3.7 Sonnet rappresenta una versione aggiornata di Claude 3.5 Sonnet. Nella modalità di pensiero esteso, riflette su se stesso prima di rispondere, migliorando le sue prestazioni in matematica, fisica, seguire le istruzioni, codifica e molti altri compiti. In genere troviamo che la richiesta del modello funziona in modo simile in entrambe le modalità.
In secondo luogo, quando si utilizza Claude 3.7 Sonnet tramite l'API, gli utenti possono anche controllare il budget per il pensiero: si può dire a Claude di pensare per non più di N gettoni, per qualsiasi valore di N fino al suo limite di uscita di 128K gettoni. In questo modo, è possibile scambiare la velocità (e il costo) con la qualità della risposta.
In terzo luogo, nello sviluppo dei nostri modelli di ragionamento, abbiamo ottimizzato un po' meno per i problemi delle competizioni matematiche e informatiche, spostando invece l'attenzione sui compiti del mondo reale che riflettono meglio il modo in cui le aziende utilizzano effettivamente gli LLM.
I primi test hanno dimostrato la leadership di Claude nelle capacità di codifica su tutta la linea: Cursor ha notato che Claude è ancora una volta il migliore della categoria per i compiti di codifica del mondo reale, con miglioramenti significativi in aree che vanno dalla gestione di codebase complessi all'uso di strumenti avanzati. Cognition l'ha trovato molto migliore di qualsiasi altro modello nella pianificazione delle modifiche al codice e nella gestione degli aggiornamenti full-stack. Vercel ha evidenziato l'eccezionale precisione di Claude per i complessi flussi di lavoro degli agenti, mentre Replit ha impiegato con successo Claude per costruire sofisticate applicazioni web e dashboard da zero, dove altri modelli si bloccano. Nelle valutazioni di Canva, Claude ha prodotto costantemente codice pronto per la produzione, con un gusto progettuale superiore e una drastica riduzione degli errori.
Grafico a barre che mostra Claude 3.7 Sonnet come lo stato dell'arte per SWE-bench Verificato
Claude 3.7 Sonnet raggiunge lo stato dell'arte delle prestazioni in SWE-bench Verified, che valuta la capacità dei modelli AI di risolvere i problemi del software del mondo reale. Per maggiori informazioni sullo scaffolding, vedere l'appendice.
Grafico a barre che mostra Claude 3.7 Sonnet come stato dell'arte per TAU-bench
Claude 3.7 Sonnet raggiunge prestazioni all'avanguardia su TAU-bench, un framework che testa gli agenti AI su compiti complessi del mondo reale con interazioni con l'utente e con gli strumenti. Per maggiori informazioni sullo scaffolding, vedere l'appendice.
Tabella di benchmark che confronta i modelli di ragionamento di frontiera
Claude 3.7 Sonnet eccelle nel seguire le istruzioni, nel ragionamento generale, nelle capacità multimodali e nella codifica agenziale, con il pensiero esteso che fornisce un notevole impulso in matematica e scienze. Al di là dei benchmark tradizionali, ha persino superato tutti i modelli precedenti nei nostri test di gameplay Pokémon.
Codice Claude
Da giugno 2024, Sonnet è il modello preferito dagli sviluppatori di tutto il mondo. Oggi, stiamo potenziando ulteriormente gli sviluppatori introducendo Claude Code - il nostro primo strumento di codifica agonica - in un'anteprima di ricerca limitata.
Claude Code è un collaboratore attivo che può cercare e leggere il codice, modificare i file, scrivere ed eseguire test, eseguire il commit e il push del codice su GitHub e utilizzare gli strumenti della riga di comando, mantenendola nel loop in ogni fase.
Claude Code è un prodotto agli inizi, ma è già diventato indispensabile per il nostro team, soprattutto per lo sviluppo guidato dai test, il debug di problemi complessi e il refactoring su larga scala. Nei primi test, Claude Code ha completato in un solo passaggio attività che normalmente richiederebbero 45+ minuti di lavoro manuale, riducendo i tempi di sviluppo e le spese generali.
Nelle prossime settimane, prevediamo di migliorarlo continuamente in base al nostro utilizzo: migliorare l'affidabilità delle chiamate agli strumenti, aggiungere il supporto per i comandi di lunga durata, migliorare il rendering in-app e ampliare la comprensione delle capacità di Claude stesso.
Il nostro obiettivo con Claude Code è capire meglio come gli sviluppatori utilizzano Claude per la codifica, per informare i futuri miglioramenti del modello. Partecipando a questa anteprima, avrà accesso agli stessi potenti strumenti che utilizziamo per costruire e migliorare Claude, e il suo feedback darà forma diretta al suo futuro.
Lavorare con Claude sulla sua base di codice
Abbiamo anche migliorato l'esperienza di codifica su Claude.ai. La nostra integrazione con GitHub è ora disponibile su tutti i piani Claude, consentendo agli sviluppatori di collegare i loro repository di codice direttamente a Claude.
Claude 3.7 Sonnet è il nostro miglior modello di codifica fino ad oggi. Con una comprensione più profonda dei suoi progetti personali, lavorativi e open source, diventa un partner più potente per la correzione di bug, lo sviluppo di funzionalità e la creazione di documentazione sui suoi progetti GitHub più importanti.
Costruire in modo responsabile
Abbiamo condotto test e valutazioni approfondite su Claude 3.7 Sonnet, collaborando con esperti esterni per garantire che soddisfi i nostri standard di sicurezza, protezione e affidabilità. Claude 3.7 Sonnet fa anche distinzioni più sfumate tra richieste dannose e benigne, riducendo i rifiuti inutili del 45% rispetto al suo predecessore.
La scheda di sistema per questa release riguarda i nuovi risultati di sicurezza in diverse categorie, fornendo una ripartizione dettagliata delle valutazioni della nostra Politica di Scalabilità Responsabile che altri laboratori e ricercatori di AI possono applicare al loro lavoro. La scheda affronta anche i rischi emergenti legati all'uso del computer, in particolare gli attacchi di tipo prompt injection, e spiega come valutiamo queste vulnerabilità e addestriamo Claude a resistere e a mitigarle. Inoltre, esamina i potenziali benefici per la sicurezza derivanti dai modelli di ragionamento: la capacità di capire come i modelli prendono le decisioni e se il ragionamento dei modelli è veramente degno di fiducia e affidabile. Per saperne di più, legga la scheda completa del sistema.
Guardare avanti
Claude 3.7 Sonnet e Claude Code segnano un passo importante verso sistemi di intelligenza artificiale che possano davvero aumentare le capacità umane. Con la loro capacità di ragionare in profondità, di lavorare in modo autonomo e di collaborare in modo efficace, ci avvicinano a un futuro in cui l'AI arricchisce ed espande ciò che gli esseri umani possono raggiungere.
Timeline delle tappe che mostra i progressi di Claude da assistente a pioniere
Non vediamo l'ora che lei possa esplorare queste nuove capacità e vedere cosa creerà con esse. Come sempre, accogliamo il suo feedback mentre continuiamo a migliorare ed evolvere i nostri modelli.
Appendice
1 Lezione appresa sulla denominazione.
Fonti di dati di valutazione
Grok
Gemini 2 Pro
o1 e o3-mini
Supplemento o1
o1 TAU-bench
Supplemento o3-mini
Deepseek R1
TAU-bench
Informazioni sullo scaffolding
I punteggi sono stati ottenuti con un'aggiunta alla Politica dell'Agente di Linea che istruisce Claude a utilizzare meglio uno strumento di "pianificazione", in cui il modello è incoraggiato a scrivere i suoi pensieri mentre risolve il problema in modo diverso dalla nostra modalità di pensiero abituale, durante le traiettorie multigiro per sfruttare al meglio le sue capacità di ragionamento. Per adattarsi ai passi aggiuntivi che Claude incorre utilizzando una maggiore capacità di ragionamento, il numero massimo di passi (contato dai completamenti del modello) è stato aumentato da 30 a 100 (la maggior parte delle traiettorie si è completata sotto i 30 passi, con una sola traiettoria che ha superato i 50 passi).
Inoltre, il punteggio TAU-bench per Claude 3.5 Sonnet (nuovo) differisce da quello che abbiamo riportato originariamente al momento del rilascio, a causa di piccoli miglioramenti del set di dati introdotti da allora. Abbiamo ripetuto l'analisi sul set di dati aggiornato per un confronto più accurato con Claude 3.7 Sonnet.
SWE-bench verificato
Informazioni sullo scaffolding
Esistono molti approcci per risolvere compiti agici aperti come SWE-bench. Alcuni approcci scaricano gran parte della complessità di decidere quali file indagare o modificare e quali test eseguire a un software più tradizionale, lasciando al modello linguistico centrale il compito di generare codice in punti predefiniti o di selezionare da un insieme più limitato di azioni. Agentless (Xia et al., 2024) è un quadro popolare utilizzato nella valutazione di R1 di Deepseek e di altri modelli, che aumenta un agente con meccanismi di reperimento di file basati su prompt e embedding, localizzazione di patch e campionamento di rifiuto best-of-40 rispetto ai test di regressione. Altri scaffold (ad esempio, Aide) integrano ulteriormente i modelli con un calcolo supplementare nel tempo del test, sotto forma di tentativi, best-of-N o Monte Carlo Tree Search (MCTS).
Per Claude 3.7 Sonnet e Claude 3.5 Sonnet (nuovo), utilizziamo un approccio molto più semplice con uno scaffolding minimo, in cui il modello decide quali comandi eseguire e quali file modificare in una singola sessione. Il nostro risultato principale "senza pensiero esteso" pass@1 equipaggia semplicemente il modello con i due strumenti descritti qui - uno strumento bash e uno strumento di editing di file che opera tramite sostituzioni di stringhe - oltre allo "strumento di pianificazione" menzionato sopra nei nostri risultati TAU-bench. A causa dei limiti dell'infrastruttura, solo 489/500 problemi sono effettivamente risolvibili sulla nostra infrastruttura interna (cioè, la soluzione d'oro supera i test). Per il nostro punteggio vanilla pass@1, contiamo gli 11 problemi irrisolvibili come fallimenti per mantenere la parità con la classifica ufficiale. Per trasparenza, pubblichiamo separatamente i casi di test che non hanno funzionato sulla nostra infrastruttura.
Per il nostro numero "ad alto calcolo", adottiamo una complessità aggiuntiva e un calcolo parallelo del tempo di prova come segue:
Campioniamo più tentativi paralleli con lo scaffold di cui sopra
Scartiamo le patch che rompono i test di regressione visibili nel repository, in modo simile all'approccio di campionamento del rifiuto adottato da Agentless; si noti che non vengono utilizzate informazioni sui test nascosti.
Classifichiamo poi i tentativi rimanenti con un modello di punteggio simile ai nostri risultati su GPQA e AIME descritti nel nostro post di ricerca e scegliamo il migliore per l'invio.
Questo risulta in un punteggio del 70,3% sul sottoinsieme di n=489 compiti verificati che funzionano sulla nostra infrastruttura. Senza questo scaffold, Claude 3.7 Sonnet ottiene il 63,7% su SWE-bench Verified utilizzando questo stesso sottoinsieme. Gli 11 casi di test esclusi che erano incompatibili con la nostra infrastruttura interna sono:
scikit-learn__scikit-learn-14710
django__django-10097
psf__richieste-2317
sphinx-doc__sphinx-10435
sphinx-doc__sphinx-7985
sphinx-doc__sphinx-8475
matplotlib__matplotlib-20488
astropy__astropy-8707
astropy__astropy-8872
sphinx-doc__sphinx-8595
sphinx-doc__sphinx-9711









